第 27 章 簡單線性迴歸 Simple Linear Regression
- Far better an approximate answer to the right question, which is often vague, than an exact answer to the wrong questions, which can always be made precise.
- John Tukey
27.1 一些背景和術語
思考下面這些問題:
- 脂肪攝入量增加,會導致體重增加嗎?
- 兒童成年時的身高,可以用父母親的身高來預測嗎?
- 如果其他條件都沒有變化,飲食習慣的改變,是否能影響血清膽固醇的水平?
上面的問題中,自變量 (預測變量),和因變量 (反應量) 分別是什麼?
你可能還會碰到像下面這些稱呼,他們都是一個意思:
- 因變量 Dependent variable = 反應量 response variable = 結果變量 outcome variable;
- 自變量 independent variable = 預測變量 predictor variable = 解釋變量 explanatory variable = 共變量 covariate.
所有的非簡單統計模型 (non-trivial statistical models) 都包括以下三個部分:
- 隨機變量 random variables:
- 因變量永遠都是隨機變量;
- 預測變量不一定是隨機變量;
- 在相對簡單的模型中,我們討論的因變量和預測變量幾乎都來自於從人羣中抽取觀察樣本收集來的數據。
- 人羣參數 population parameters:
- 人羣參數,是我們希望通過收集樣本獲得的數據來估計 (estimate) 的參數。
- 對不確定性的描述 representation of uncertainty:
- 不確定性,意爲因變量的變動中,沒有被預測變量解釋的部分。
其他的術語問題:
- 單一因變量的統計模型:univariate model;
- 多個因變量的統計模型: multivariate model;
- 單一因變量,含有多個預測變量的統計模型:multivariable model;
- 在線性迴歸中,單一因變量,單一預測變量的統計模型:simple linear regression (簡單線性迴歸);
- 在線性迴歸中,單一因變量,多個預測變量的統計模型:multiple linear regression (多重線性迴歸);
儘量避免將預測變量 (predictor variable) 寫作自變量 (independent variable),因爲 “independent” 有自己的統計學含義 (獨立)。然而我們在線性迴歸中使用的預測變量,不一定都互相獨立,所以容易讓人混淆其意義。
27.2 簡單線性迴歸模型 simple linear regression model
即:單一因變量,單一預測變量的統計模型。
27.2.1 數據 A
下面的散點圖 27.1 展示的是一項橫斷面調查的結果,調查的是一些兒童的年齡 (月),和他們的體重 (千克) 之間的關係。
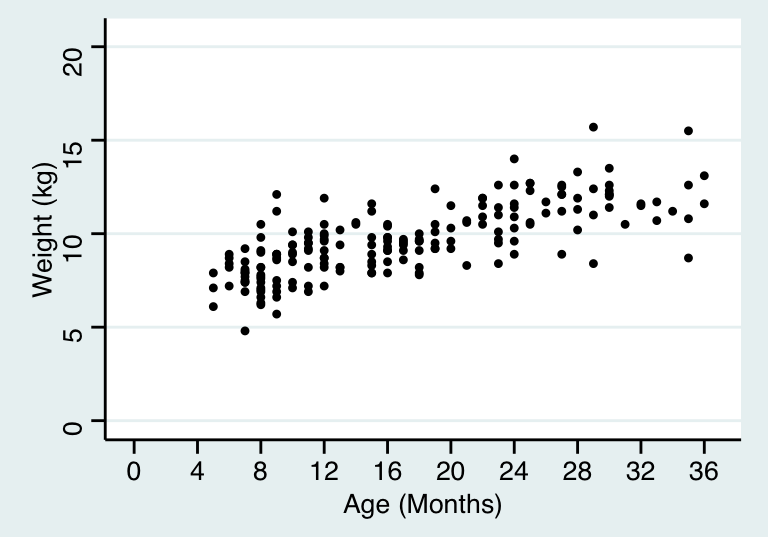
圖 27.1: Age and weight of children in a cross-sectional survey
27.2.2 數據 B
表 27.1 羅列的是11名兒童能夠自己獨立行走時的年齡。這些兒童在剛出生時被隨機分配到兩個組中 (積極鍛鍊走路,和對照組)。如果你熟悉均數比較,這樣的數據可以通過簡單 \(t\) 檢驗來分析其均值的不同。但是實際上後面你會看到簡單 \(t\) 檢驗和簡單線性迴歸是同一回事。
| Active Exercise (n=6) | Eight Week Control (n=5) |
|---|---|
| 9.00 | 13.25 |
| 9.50 | 11.5 |
| 9.75 | 12 |
| 10.00 | 13.5 |
| 13.00 | 11.5 |
| 9.50 | – |
27.3 區分因變量和預測變量
在簡單兩樣本 \(t\) 檢驗中,我們不區分那兩個要比較的數據 \((X, Y)\)。所以 \(X\) 和 \(Y\) 的關係,同分析 \(Y\) 和 \(X\) 的關係是一樣的。表 27.1 的例子中,視“直立行走的年齡”這一變量爲因變量十分直觀且自然。圖 27.1 的例子中我們顯然可以關心是否可以用兒童的年齡來推測他/她的體重。所以年齡被視爲預測變量 \((X)\),體重被視爲因變量或者叫結果變量 \((Y)\)。
27.3.1 均值 (期待值) 公式
圖 27.1 的例子中,當我們決定考察體重變化 \((Y)\) 和年齡的關係 \((X)\) 後,我們需要提出一個模型,來描述二者之間的關係。這個模型中,最重要的信息,是均值,或者叫期待值:
\[ E(Y|X=x), \text{ the expected value of } Y \text{ when } X \text{ takes the value } x \]
在簡單線性迴歸模型中,我們認爲這個均值方程是線性關係:
\[ E(Y|X=x) = \alpha +\beta x \]
所以這個線性關係中,有兩個參數 (parameters) 是我們關心的 \(\alpha, \beta\)。
- \(\alpha\) 是截距 intecept。意爲當 \(X\) 取 \(0\)時, \(Y\) 的期待值大小;
- \(\beta\) 是方程的斜率 slope。意爲當 \(X\) 上升一個單位時,\(Y\) 上升的期待值大小。
需要強調的是,這樣的線性模型,是我們提出,用來模擬真實數據時使用的。你如果作死當然還可以提出更加複雜的模型。如下面圖 27.2 顯示的是線性迴歸直線, 而圖 27.3 顯示的是較爲複雜的迴歸曲線。曲線方程可能更加擬合我們收集到的數據,然而這樣的連續的斜率變化很可能僅僅只解釋了這個樣本量數據,而不能解釋在人羣中年齡和體重的關係。
library(haven)
library(ggplot2)
library(ggthemes)
growgam1 <- read_dta("../backupfiles/growgam1.dta")
ggplot(growgam1, aes(x=age, y=wt)) + geom_point(shape=20, colour="grey40") +
stat_smooth(method = lm, size = 0.3) +
scale_x_continuous(breaks=seq(0, 38, 4),limits = c(0,36.5))+
scale_y_continuous(breaks = seq(0, 20, 5),limits = c(0,20.5)) +
theme_stata() +labs(x = "Age (Months)", y = "Weight (kg)")## `geom_smooth()` using formula 'y ~ x'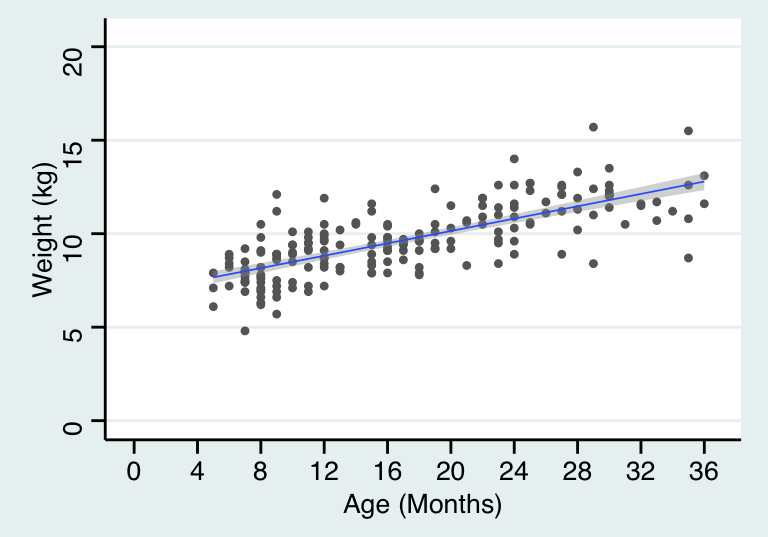
圖 27.2: Linear mean function for age and weight of children in a cross-sectional survey
library(haven)
library(ggplot2)
library(ggthemes)
growgam1 <- read_dta("../backupfiles/growgam1.dta")
ggplot(growgam1, aes(x=age, y=wt)) + geom_point(shape=20, colour="grey40") +
stat_smooth(method = loess, se=T, size = 0.3) +
scale_x_continuous(breaks=seq(0, 38, 4),limits = c(0,36.5))+
scale_y_continuous(breaks = seq(0, 20, 5),limits = c(0,20.5)) +
theme_stata() +labs(x = "Age (Months)", y = "Weight (kg)")## `geom_smooth()` using formula 'y ~ x'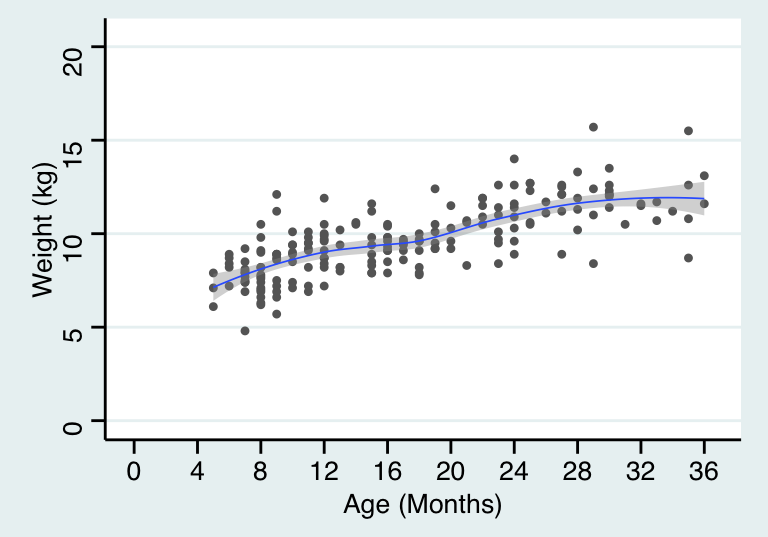
圖 27.3: Non-linear mean function for age and weight of children in a cross-sectional survey
27.3.2 條件分佈和方差 the conditional distribution and the variance function
如果要完全明確一個統計模型,另一個重要的點在於,提出的模型能否準確描述因變量在預測變量的條件下的分佈 (conditional distribution) it is necessary to describe the distribution of the dependent variable conditional on the predictor variable。使用簡單線性迴歸模型有幾個前提假設:
- 因變量對預測變量的條件分佈的方差是保持不變的 the variance of the dependent variable (conditional on the predictor variable) is constant。
- 該條件分佈是一個正態分佈。
有時候,這些假設條件並不能得到滿足。上面的散點圖 27.1看上去還算符合這兩個假設前提:在每一個年齡階段,體重的分佈沒有發生歪斜 (skew),分散分佈 (方差) 也相對穩定。但是圖 27.4 中的價格-克拉數據很明顯無法滿足上面的前提假設。在線性迴歸模型中,我們使用 \(\sigma^2\) 表示殘差的方差 (residual variance)。
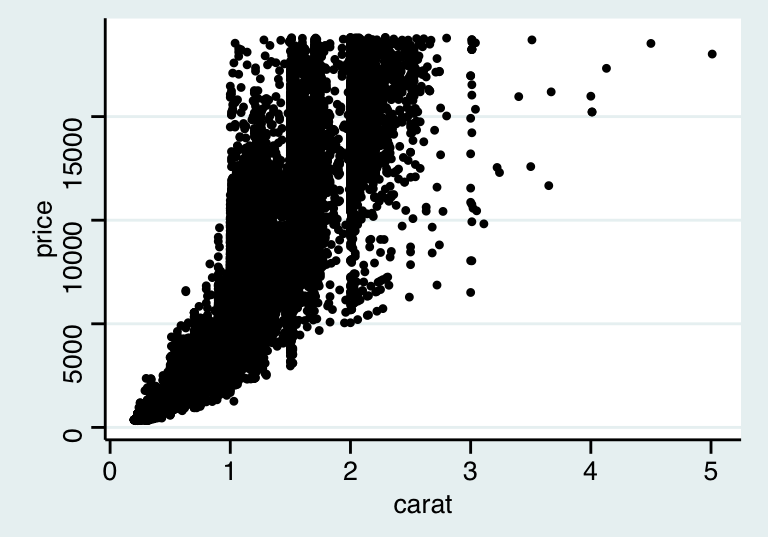
圖 27.4: Relationship between diamond carat and price
27.3.3 定義簡單線性迴歸模型
用來描述一個隨機變量 \((Y)\) 和另一個變量 \((X)\) 之間關係的簡單線性迴歸模型,被定義爲:
\[ (Y|X=x) \sim N(\alpha+\beta x, \sigma^2) \]
上面這個模型,同時還描述了我們對數據的分佈的假設。同樣的模型,你可能更多得看到被寫成如下的方式:
\[ y=\alpha+\beta x+ \varepsilon \text{, where } \varepsilon\sim N(0,\sigma^2) \]
假如,我們有一組樣本量爲 \(n\) 的數據 \(\underline{x}\)。我們就可以把通過上面的迴歸模型實現的 \(Y_i\) 和它對應的 \(X_i (i=1,\cdots, n)\)。描述爲如下的形式:
\[ \begin{equation} (Y_i|X_i=x_i) \sim \text{NID}(\alpha+\beta x, \sigma^2) \text{ where } i=1,\cdots,n \end{equation} \tag{27.1} \]
此處的 \(\text{NID}\) 意爲獨立且服從正態分佈 (normally and independently distributed)。這裏默認的一個重要前提是所有的觀察值 \(X_i\) 是相互獨立互不影響的。例如上面圖 27.1 所示兒童的年齡和體重數據,就必須假設這些兒童都來自沒有血緣關係的獨立家庭。如果這以數據中的兒童,有些是兄弟姐妹的話,觀察數據互相獨立的前提就無法得到滿足。不滿足相互獨立前提的數據,其分析方法會在 “Analysis of hierarchical and other dependent data (Term 2)” 中詳盡介紹。
公式 (27.1) 常被記爲:
\[ \begin{equation} (Y_i|X_i=x_i) = \alpha + \beta x_i + \varepsilon_i, \text{ where } \varepsilon_i\sim \text{NID}(0,\sigma^2) \end{equation} \tag{27.2} \]
或者爲了簡潔表述寫成:
\[ \begin{equation} y_i = \alpha + \beta x_i + \varepsilon_i, \text{ where } \varepsilon_i\sim \text{NID}(0,\sigma^2) \end{equation} \tag{27.3} \]
27.3.4 殘差 residuals
公式 (27.2) 和 (27.3) 其實已經包含了殘差的表達式:
\[ \varepsilon_i = y_i - (\alpha + \beta x_i) \]
所以 \(\varepsilon_i\) 的意義是第 \(i\) 個觀察對象的隨機(偶然)誤差 (random error),或者叫真實殘差 (true residual)。其實就是從線性迴歸模型計算獲得的映射值 \(\alpha+\beta x_i\),和實際觀察值 \(y_i\) 之間的差距。而且從其公式可見,殘差本身也是由人羣的參數 \((\alpha, \beta)\) 決定的。殘差也被定義爲迴歸模型的偏差值。當我們用樣本數據獲得的參數估計 \((\hat\alpha, \hat\beta)\) 來取代掉參數 \((\alpha, \beta)\) 時,這時的模型變成了估計模型,殘差也成了估計殘差或者叫觀察模型和觀察殘差。須和真實殘差加以區分。
27.4 參數的估計 estimation of parameters
簡單線性迴歸模型中有三個人羣參數 \((\alpha, \beta, \sigma^2)\)。統計分析的目標,就是使用樣本數據 \(Y_i, X_i, (i=1, \cdots, n)\) 來對總體參數做出推斷 (inference)。在線性迴歸中主要使用普通最小二乘法 (ordinary least squares, OLS) 作爲推斷的工具。在統計學中,我們習慣給希臘字母戴上“帽子”,作爲該參數的估計值,例如 \(\hat\alpha, \hat\beta\) 是參數 \(\alpha, \beta\) 的估計值。通過線性迴歸模型,給第 \(i\) 個觀察值擬合的預測值,被叫做因變量的估計期望值 (estimated expectation)。用下面的式子來表示:
\[ \hat{y}_i=\hat\alpha+\hat\beta x_i \]
此時,第 \(i\) 名對象的觀察殘差 (observed or fitted or estimated residuals) 用下面的式子來表示:
\[ \hat{\varepsilon}_i = y_i-\hat{y}_i=y_i-(\hat\alpha+\hat\beta x_i) \]
27.4.1 普通最小二乘法估計 \(\alpha, \beta\)
普通最小二乘法估計的 \(\alpha, \beta\) 會最小化擬合迴歸直線的偏差 minimize the sum of squared deviations from the fitted regression line。其正式的定義爲:OLS估計值,指的是能夠使殘差平方和 (residual sum of squares, \(SS_{RES}\))取最小值的 \(\hat\alpha, \hat\beta\)。
\[ \begin{equation} SS_{RES} = \sum_{i=1}^n \hat{\varepsilon}^2_i = \sum_{i=1}^n (y_i-\hat\alpha-\hat\beta x_i)^2 \end{equation} \tag{27.4} \]
可以證明的是,OLS的 \(\alpha, \beta\) 估計值的計算公式爲:
\[ \begin{equation} \hat\alpha=\bar{y}-\hat\beta\bar{x} \tag{27.5} \end{equation} \]
\[ \begin{equation} \hat\beta=\frac{\sum_{i=1}^n(x_i-\bar{x})(y_i-\bar{y})}{\sum_{i=1}^n(x_i-\bar{x})^2} \tag{27.6} \end{equation} \]
其中 \(\bar{y}=\frac{\sum_{i=1}^ny_i}{n}, \bar{x}=\frac{\sum_{i=1}^nx_i}{n}\)
證明
求能最小化 \(SS_{RES}\) 的 \(\alpha\), 我們需要把公式 (27.4) 對 \(\hat\alpha\) 求導,然後將求導之後的式子等於 \(0\) 之後求根即可:
\[ \begin{aligned} & \frac{\text{d}SS_{RES}}{\text{d}\hat\alpha} =\sum_{i=1}^n -2(y_i-\hat\alpha-\hat\beta x_i) = 0\\ & \text{Since } \sum_{i=1}^n(y_i) = n\bar{y}; \sum_{i=1}^n (x_i) =n\bar{x} \\ & \Rightarrow -n\bar{y}+n\hat\alpha+n\hat\beta\bar{x} = 0 \\ & \Rightarrow \hat\alpha = \bar{y}-\hat\beta\bar{x} \end{aligned} \]
求能最小化 \(SS_{RES}\) 的 \(\beta\),求導之前我們先把公式 (27.4) 中含有 \(\hat\alpha\) 的部分替換掉:
\[ \begin{equation} \begin{split} SS_{RES} &= \sum_{i=1}^n\hat\varepsilon_i^2=\sum_{i=1}^n(y_i-(\bar{y}-\hat\beta\bar{x})-\hat\beta x_i)^2\\ &= \sum_{i=1}^n((y_i-\bar{y})-\hat\beta(x_i-\bar{x}))^2 \\ \end{split} \tag{27.7} \end{equation} \]
接下來對上式 (27.7) 求導之後,用相同辦法求根:
\[ \begin{aligned} &\frac{\mathrm{d} SS_{RES}}{\mathrm{d} \hat\beta} = \sum_{i=1}^n -2(x_i-\bar{x})(y_i-\bar{y}) + 2\hat\beta(x_i-\bar{x})^2 = 0\\ & \Rightarrow \hat\beta\sum_{i=1}^n(x_i-\bar{x})^2 = \sum_{i=1}^n (x_i-\bar{x})(y_i-\bar{y}) \\ & \hat\beta=\frac{\sum_{i=1}^n(x_i-\bar{x})(y_i-\bar{y})}{\sum_{i=1}^n(x_i-\bar{x})^2} \end{aligned} \]
27.5 殘差方差的估計 Estimation of the residual variance \((\sigma^2)\)
殘差方差等於殘差平方和除以樣本量。所以我們會把殘差方差的估計用下面的式子表示:
\[ \begin{equation} \hat\sigma^2=\sum_{i=1}^n \frac{\hat\varepsilon^2}{n} = \sum_{i=1}^n \frac{(y_i-\hat\alpha-\hat\beta x_i)^2}{n} \end{equation} \tag{27.8} \]
這的確是 \(\sigma^2\) 的極大似然估計 (MLE)。然而我們知道,公式 (27.8) 並不是殘差方差的無偏估計。類似與樣本方差低估了總體方差 (Section 10.3),那樣,這裏殘差方差的觀察值也是低估了總體殘差方差的。所以,殘差方差的無偏估計需要用下面的式子來校正:
\[ \begin{equation} \hat\sigma^2=\sum_{i=1}^n \frac{\hat\varepsilon^2}{n-2} = \sum_{i=1}^n \frac{(y_i-\hat\alpha-\hat\beta x_i)^2}{n-2} \end{equation} \tag{27.9} \]
公式 (27.9) 被叫做殘差均方 (Residual Mean Squares, RMS),常常被標記爲 \(\text{MS}_{RES}\)。分母的 \(n-2\),表示進行殘差方差估計時用掉了兩個信息量 \(\alpha, \beta\) (自由度減少了 2),
27.6 R 演示 例 1: 圖 27.1 數據
library(haven)
growgam1 <- read_dta("../backupfiles/growgam1.dta")
slm <- lm(wt~age, data=growgam1)
summary(slm) # basic default output of the summary##
## Call:
## lm(formula = wt ~ age, data = growgam1)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.924 -0.785 0.007 0.797 4.068
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 6.8376 0.2101 32.5 <2e-16 ***
## age 0.1653 0.0111 14.9 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.27 on 188 degrees of freedom
## Multiple R-squared: 0.541, Adjusted R-squared: 0.538
## F-statistic: 221 on 1 and 188 DF, p-value: <2e-16## Analysis of Variance Table
##
## Response: wt
## Df Sum Sq Mean Sq F value Pr(>F)
## age 1 359.06320 359.06320 221.39203 < 2.22e-16 ***
## Residuals 188 304.90655 1.62184
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1也可以用 stargazer 包輸出很酷的表格報告:
| Dependent variable: | |
| wt | |
| age | 0.165*** |
| (0.011) | |
| Constant | 6.838*** |
| (0.210) | |
| Observations | 190 |
| R2 | 0.541 |
| Adjusted R2 | 0.538 |
| Residual Std. Error | 1.274 (df = 188) |
| F Statistic | 221.400*** (df = 1; 188) |
| Note: | p<0.1; p<0.05; p<0.01 |
其實結果都一樣。我們這裏詳細來看 \(\alpha, \beta, \sigma^2\):
\(\hat\alpha = 6.84\):當年齡爲 \(0\) 時,體重爲 \(6.84 kg\)。本數據 27.1 中並沒有 \(0\) 歲的兒童,所以這裏的截距的解釋需要非常小心是否合理。
\(\hat\beta = 0.165\):這數據中兒童的體重估計隨着年齡升高 \(1\) 個月增長 \(0.165 kg\)。所以使用這兩個估計值我們就可以來估計任意年齡時兒童的體重。圖 27.2 就是擬合數據以後的簡單線性迴歸曲線。
\(\hat\sigma^2 = 1.62, \hat\sigma=1.27\) 就是默認輸出中最下面的 Residual standard error: 1.274 和 ANOVA 表格中 Residuals 的 Mean Sq=1.62184 部分。含義是,沿着擬合的直線,在每一個給定的年齡上兒童體重的分佈的標準差是 \(1.27 kg\)。
27.7 R 演示 例 2: 表27.1 數據
如果在 Stata 聽說你還需要自己生成啞變量 (dummy variables) (應該是計算時,在想要變成啞變量的變量名前面加上 i.)。在 R 裏面,分類變量被設置成因子 “factor” 時,你就完全可以忽略生成啞變量的過程。下圖 27.5 顯示了兩組兒童直立行走時的年齡。
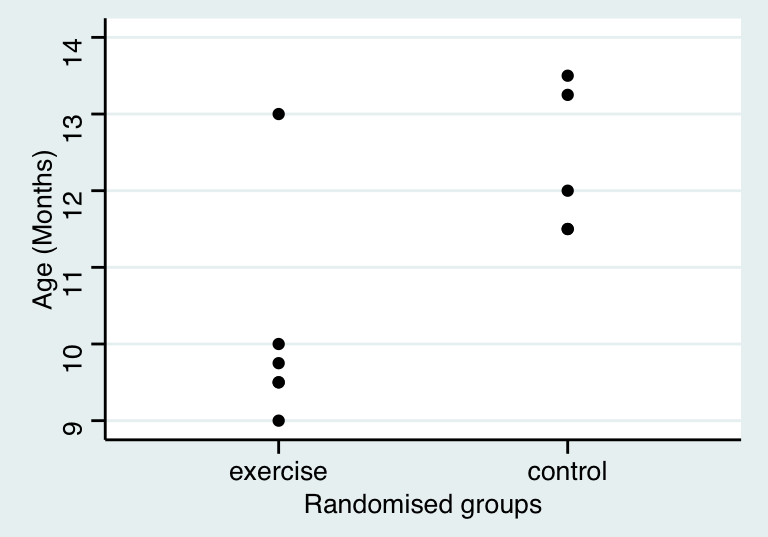
圖 27.5: Age at walking by group
擬合簡單線性迴歸也是小菜一碟:
##
## Call:
## lm(formula = Age ~ Group, data = Walk)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.125 -0.738 -0.375 0.388 2.875
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 10.125 0.512 19.77 1e-08 ***
## Groupcontrol 2.225 0.760 2.93 0.017 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.25 on 9 degrees of freedom
## (1 observation deleted due to missingness)
## Multiple R-squared: 0.488, Adjusted R-squared: 0.431
## F-statistic: 8.58 on 1 and 9 DF, p-value: 0.0168## Analysis of Variance Table
##
## Response: Age
## Df Sum Sq Mean Sq F value Pr(>F)
## Group 1 13.5 13.50 8.58 0.017 *
## Residuals 9 14.2 1.57
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1這裏的 \(\hat\alpha=10.125\),意爲參照組 (此處,“exercise” 被默認設定爲參照組,而 “control” 被默認拿來和參照組相比較) 的兒童也就是,積極練習走路的小朋友這組能夠獨立行走的平均年齡是 \(10.125\) 個月。
\(\hat\beta=2.225\),意爲和參照組 (積極練習組) 相比,對照組兒童能夠自己行走的年齡平均要晚 \(2.225\) 個月。所以對照組兒童能夠直立行走的平均年齡就是 \(10.125+2.225=12.35\) 個月。
上述結果,你如果拿來和下面的兩樣本 \(t\) 檢驗的結果相比就知道,是完全一致的。其中統計量 \(t^2=2.9285^2=F_{1,9}=8.58\)。
##
## Two Sample t-test
##
## data: Age by Group
## t = -2.9, df = 9, p-value = 0.02
## alternative hypothesis: true difference in means between group exercise and group control is not equal to 0
## 95 percent confidence interval:
## -3.9437 -0.5063
## sample estimates:
## mean in group exercise mean in group control
## 10.12 12.3527.8 LM practical 01
使用的數據內容爲:兩次調查同一樣本,99 名健康男性的血清膽固醇水平,間隔一年。
## id chol1 chol2
## Min. : 1.0 Min. :152 Min. :170
## 1st Qu.:25.5 1st Qu.:235 1st Qu.:240
## Median :50.0 Median :265 Median :260
## Mean :50.0 Mean :265 Mean :264
## 3rd Qu.:74.5 3rd Qu.:290 3rd Qu.:290
## Max. :99.0 Max. :360 Max. :355## Chol
##
## 3 Variables 99 Observations
## ----------------------------------------------------------------------------------------------------
## id Format:%9.0g
## n missing distinct Info Mean Gmd .05 .10 .25 .50 .75
## 99 0 99 1 50 33.33 5.9 10.8 25.5 50.0 74.5
## .90 .95
## 89.2 94.1
##
## lowest : 1 2 3 4 5, highest: 95 96 97 98 99
## ----------------------------------------------------------------------------------------------------
## chol1 Format:%9.0g
## n missing distinct Info Mean Gmd .05 .10 .25 .50 .75
## 99 0 51 0.999 264.6 46.11 204.5 210.0 235.0 265.0 290.0
## .90 .95
## 320.0 330.3
##
## lowest : 152 170 190 200 205, highest: 333 340 350 355 360
## ----------------------------------------------------------------------------------------------------
## chol2 Format:%9.0g
## n missing distinct Info Mean Gmd .05 .10 .25 .50 .75
## 99 0 30 0.997 263.5 43.28 200 215 240 260 290
## .90 .95
## 311 330
##
## lowest : 170 190 195 200 205, highest: 320 330 345 350 355
## ----------------------------------------------------------------------------------------------------
# 對兩次膽固醇水平作散點圖
ggplot(Chol, aes(x=chol1, y=chol2)) + geom_point(shape=20) +
scale_x_continuous(breaks=seq(150, 400, 50),limits = c(150, 355))+
scale_y_continuous(breaks=seq(150, 400, 50),limits = c(150, 355)) +
theme_stata() +labs(x = "Cholesterol at visit 1 (mg/100ml)", y = "Cholesterol at visit 2 (mg/100ml)")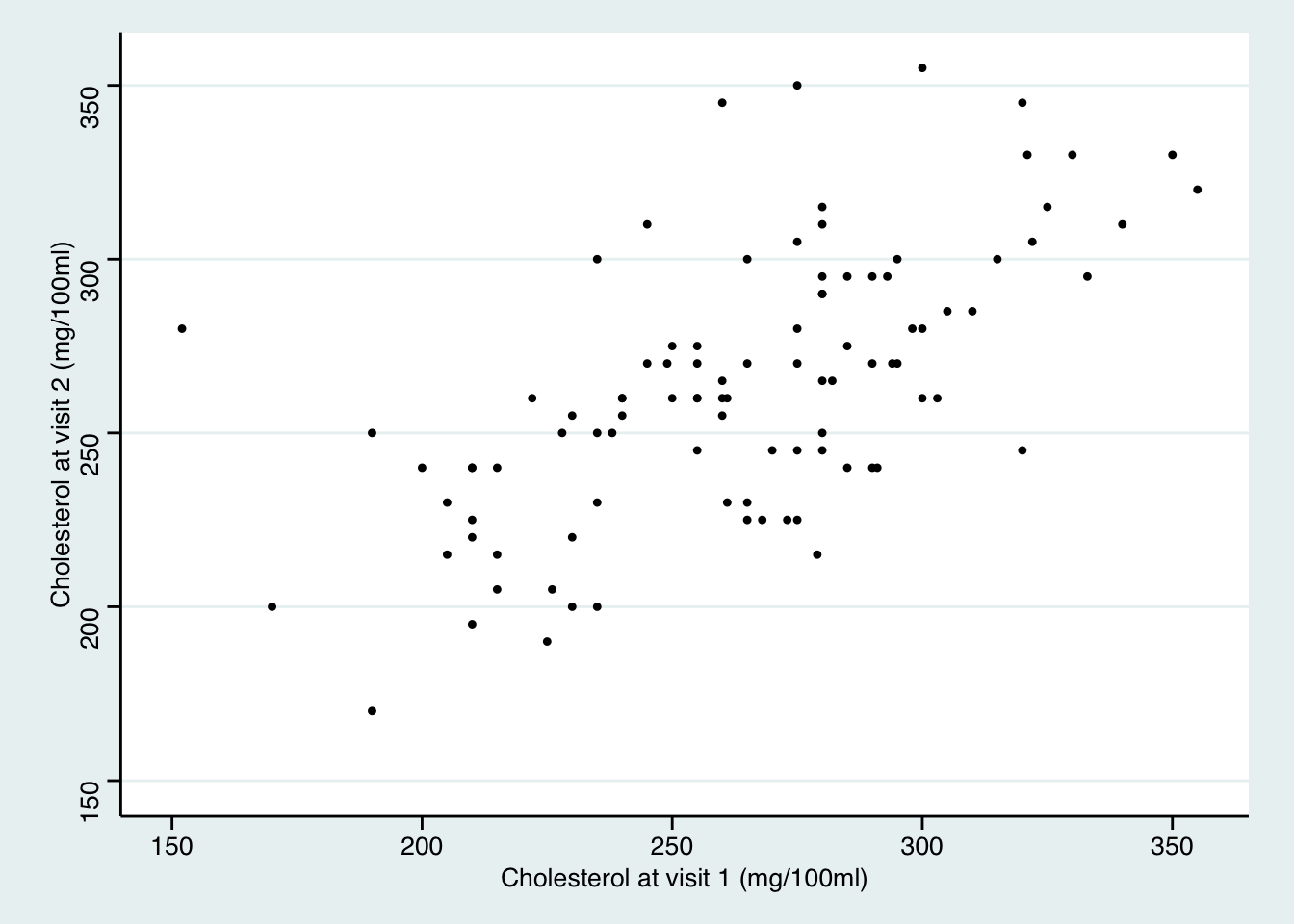
27.8.1 兩次測量的膽固醇水平分別用 \(C_1, C_2\) 來標記的話,考慮這樣的簡單線性迴歸模型:\(C_2=\alpha+\beta C_2 + \varepsilon\)。我們進行這樣迴歸的前提假設有哪些?
- 每個觀察對象互相獨立。
- 前後兩次測量的膽固醇水平呈線性相關。
- 殘差值,在每一個給定的 \(C_1\) 值處呈現正態分佈,且方差不變。
從散點圖來看這些假設應該都能得到滿足。
## [1] 264.6## [1] 263.5## [1] 1661## [1] 1457## [1] 961.227.8.2 計算普通最小二乘法 (OLS) 下,截距和斜率的估計值 \(\hat\alpha, \hat\beta\)
\[ \begin{aligned} \hat\beta &= \frac{\sum_{i=1}^n(x_i-\bar{x})(y_i-\bar{y})}{\sum_{i=1}^n(x_i-\bar{x})^2}\\ &=\frac{\text{Cov}(C_1,C_2)}{\text{Var}(C_1)}\\ &=\frac{1661.061}{961.224}=0.578 \end{aligned} \]
## [1] 0.5787\[\hat\alpha=\bar{y}-\hat\beta\bar{x}=263.54-0.578\times264.59=110.425\]
## [1] 110.427.8.3 和迴歸模型計算的結果作比較,解釋這些估計值的含義
##
## Call:
## lm(formula = chol2 ~ chol1, data = Chol)
##
## Residuals:
## Min 1Q Median 3Q Max
## -56.88 -22.06 1.85 16.63 84.12
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 110.4247 20.0113 5.52 2.8e-07 ***
## chol1 0.5787 0.0748 7.74 9.5e-12 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 30.2 on 97 degrees of freedom
## Multiple R-squared: 0.382, Adjusted R-squared: 0.375
## F-statistic: 59.9 on 1 and 97 DF, p-value: 9.51e-12- 截距的估計值是 110.4 mg/100ml: 意爲這組樣本,第一次採集數據時,膽固醇水平的平均值是 110.4。
- 斜率的估計值是 0.58:意爲第一次採集的膽固醇水平每高 1 mg/100ml,那麼第二次採集的膽固醇相應提高的值的期待量爲 0.58.
27.8.4 加上計算的估計值直線 (即迴歸直線)
ggplot(Chol, aes(x=chol1, y=chol2)) + geom_point(shape=20, colour="grey40") +
stat_smooth(method = lm, se=FALSE, size=0.5) +
scale_x_continuous(breaks=seq(150, 400, 50),limits = c(150, 355))+
scale_y_continuous(breaks=seq(150, 400, 50),limits = c(150, 355)) +
theme_stata() +labs(x = "Cholesterol at visit 1 (mg/100ml)", y = "Cholesterol at visit 2 (mg/100ml)")## `geom_smooth()` using formula 'y ~ x'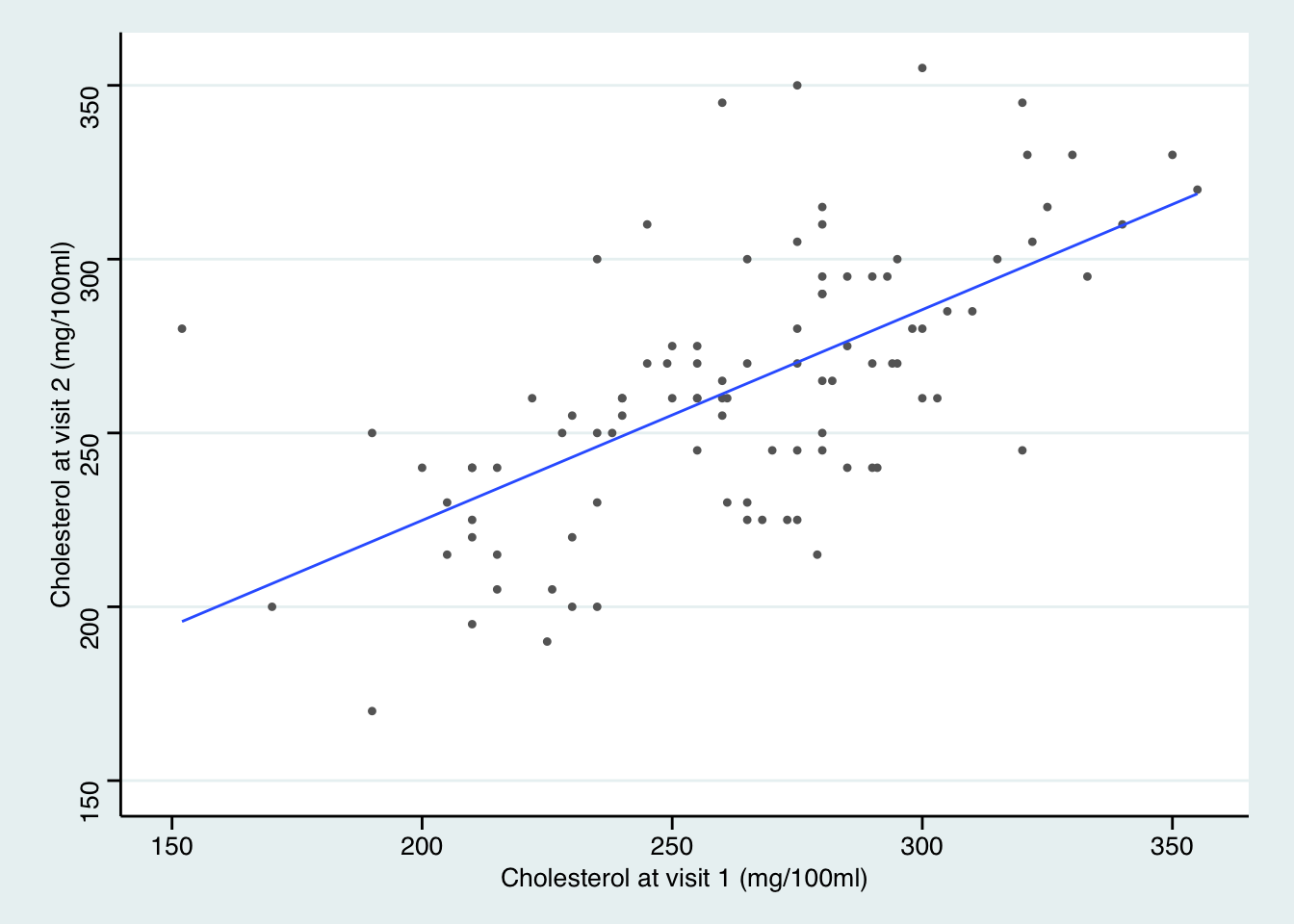
可以注意到,第一次訪問時膽固醇水平高的人,第二次被測量時膽固醇值高於平均值,但是卻沒有第一次高出平均值的部分多。 相似的,第一次膽固醇水平低的人,第二次膽固醇水平低於平均值,但是卻沒有第一次低於平均值的部分多。這一現象被叫做 “向均數迴歸-regression to the mean”
27.8.5 下面的代碼用於模型的假設診斷
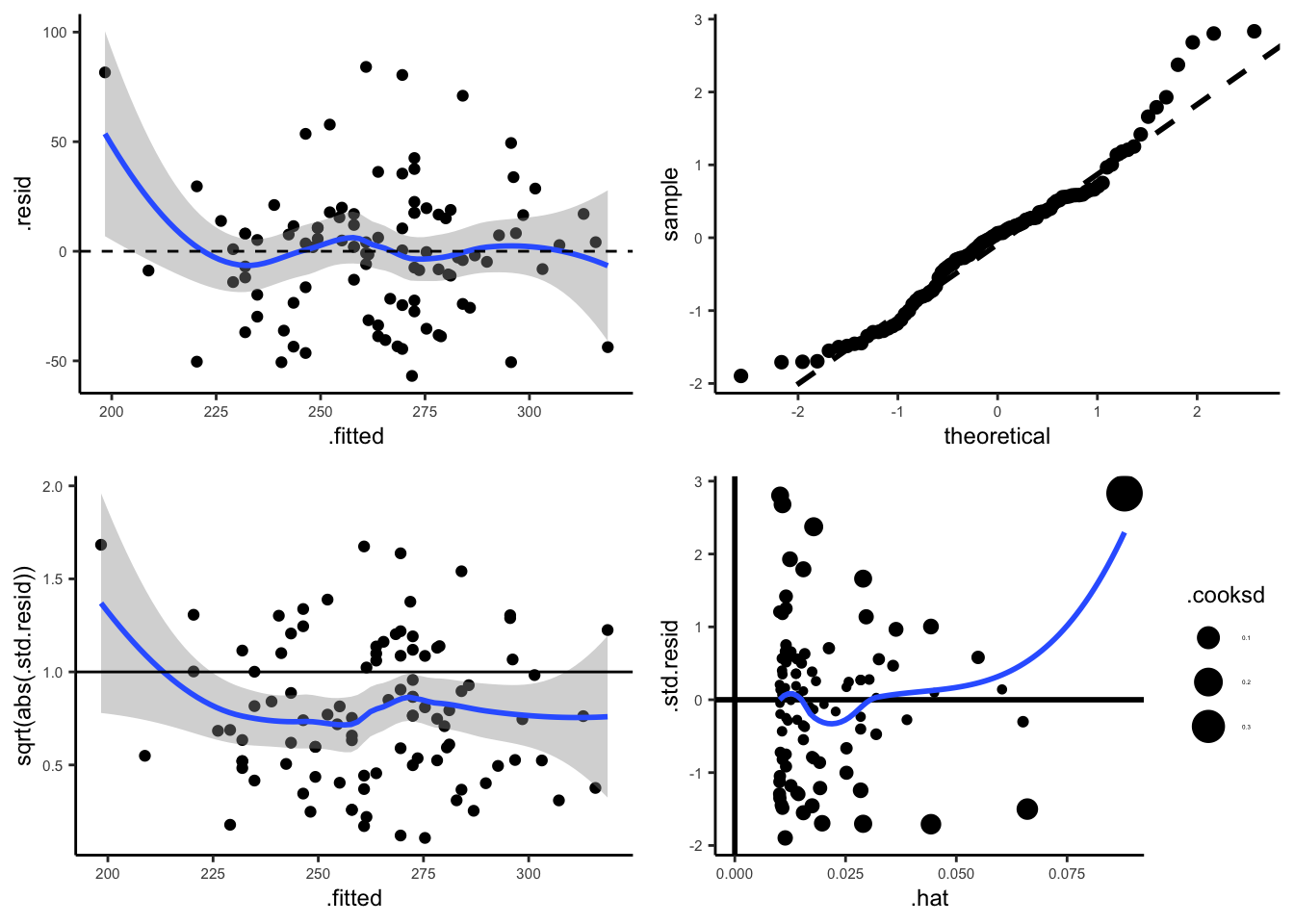
M <- lm(chol2~chol1, data=Chol)
par(mfrow = c(2, 2)) # Split the plotting panel into a 2 x 2 grid
plot(M)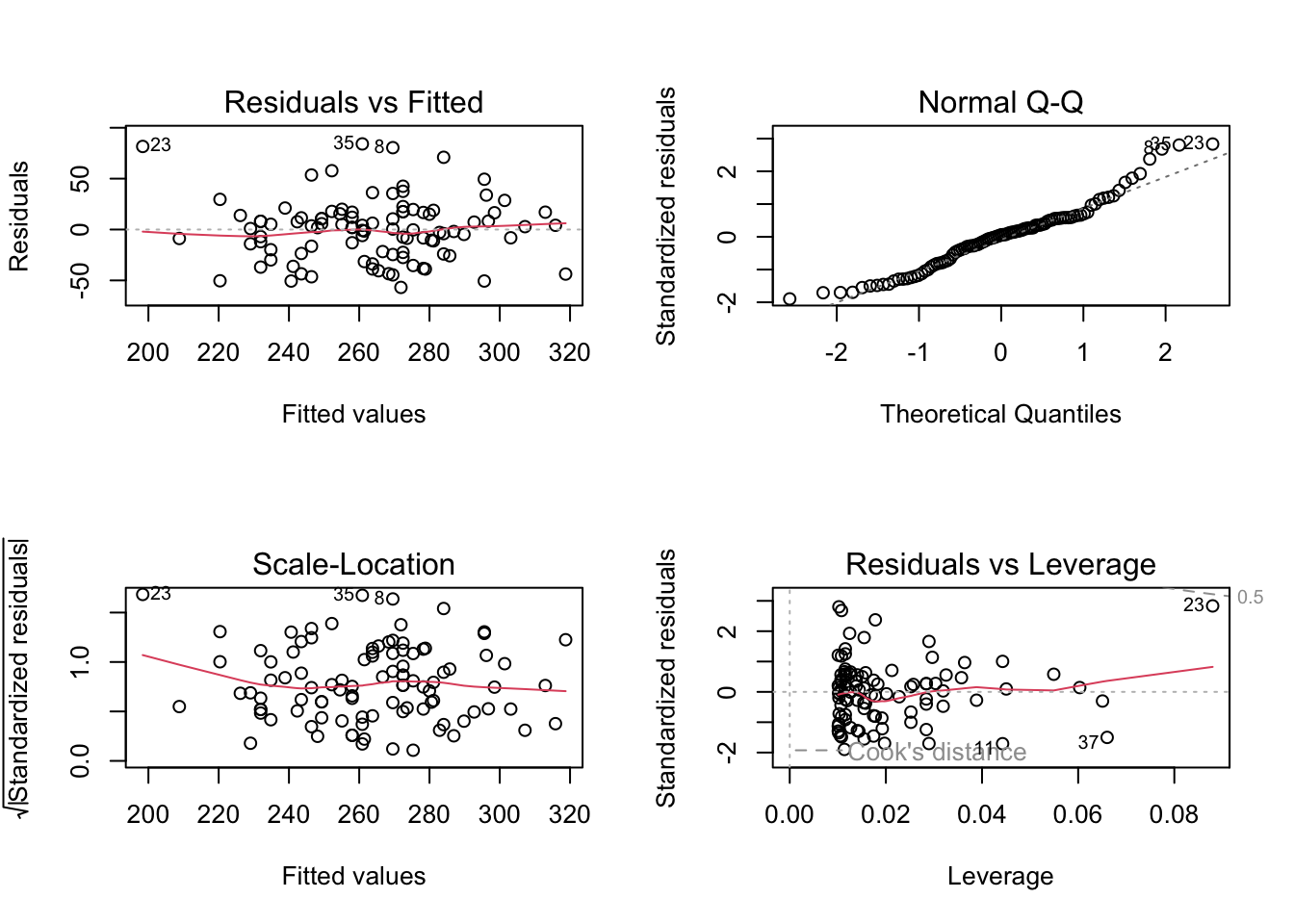
好心人在 github 上共享了 Check_assumption.R 的代碼,可以使用 ggplot2 來獲取高逼格的模型診斷圖: