第 99 章 建模和模型的檢查
對所有想要嘗試貝葉斯統計學的人來說,這個過程需要你有能力建立一個可以被用於MCMC採樣的貝葉斯模型,並且懂得怎樣獲取收斂合理,樣本量大小合適的事後概率分布樣本。下圖 99.1 中總結了建立貝葉斯統計模型並運行MCMC計算的大致過程:
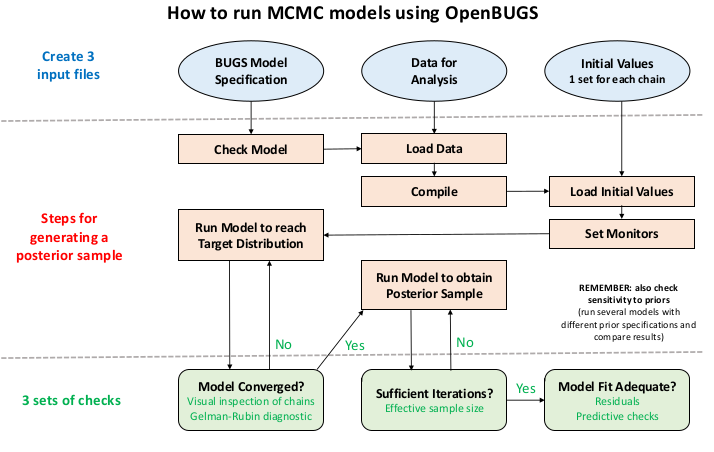
圖 99.1: Input files, steps for generating a posterior sample and checks required for successfully running a Bayesian analysis using BUGS.
虛線最上端,意爲我們需要準備三種最重要的文件:
- BUGS語言描述下的貝葉斯統計學模型;
- 包含模型中使用到的觀察變量的數據文件(可以是一個,也可是多個組合);
- 每個未知參數的MCMC採樣鏈的起始值 (initial values, 1 set for each chain)。
兩條虛線的中間部分是產生事後概率分布的重要步驟及其先後順序。虛線最下面則是三個重要的模型檢查,你需要在運行貝葉斯模型MCMC採集樣本的過程中反復使用這三個檢查模型的方案以確保過程的準確,以獲得合理的結果。
下面我們通過使用貝葉斯統計學框架來進行一個簡單線性回歸模型的計算和MCMC採集樣本的過程,詳細地解釋圖99.1中的每一個步驟及其含義。
先思考,一個只有概率論知識的統計學者,他/她是如何進行簡單線性回歸模型的擬合過程的?
- 確認觀察數據的概率分布(似然/likelihood);
- 確認結果變量和預測變量之間的合適表達式(線性回歸方程)。
這兩個步驟在貝葉斯統計學中也是不可缺少的,此外,貝葉斯統計學模型的建立和MCMC採樣還需要統計師給出回歸系數的先驗概率分布(prior distributions for the regression coefficients),以及其他未知(可能是令人感到麻煩的 nuisance)參數的先驗概率分布。
99.1 簡單線性回歸模型
如果簡單線性回歸模型的結果變量是一個服從正態分布的單一變量 \(y_i\),我們想要拿來預測這個結果變量的預測變量是從每個試驗個體 \(i, i = 1, \dots, n\) 上收集到的一系列共變量 (covariates) 的向量 \(x_{1i}, \dots, x_{pi}\)。概率論統計學者會把這樣的模型用數學表達式寫成:
\[ \begin{aligned} y_i & = \beta_0 + \sum_{k = 1}^p\beta_k x_{ki} + \epsilon_i \\ \epsilon_i & \sim \text{Normal}(0, \sigma^2) \end{aligned} \]
或者也有人習慣於把誤差項拿掉,用結果變量的期望值(也就是均值) \(E(y_i) = \mu_i\) 來寫這個模型:
\[ \begin{aligned} y_i & \sim \text{Normal}(\mu_i, \sigma^2) \\ \mu_i & = \beta_0 + \sum_{k = 1}^p\beta_k x_{ki} \end{aligned} \]
在貝葉斯框架下,這個模型的參數\((\beta_0, \beta_1, \dots, \beta_p, \sigma^2)\),還需要給出它們各自的先驗概率分布。所以貝葉斯框架下的簡單線性回歸模型的標記法是:
\[ \begin{aligned} y_i & \sim \text{Normal}(\mu_i, \sigma^2) \\ \mu_i & = \beta_0+ \sum_{k = 1}^p\beta_k x_{ki} \\ (\beta_0, \beta_1, \dots, \beta_p, \sigma^2) & \sim \text{ Prior Distributions} \end{aligned} \]
如果想要獲得和概率論的簡單線性回歸模型的算法(OLS, ordinary least squares / MLE, maximum likelihood estimates)獲得的結果接近的參數估計,那麼先驗概率分布可以指定爲:
\[ \begin{aligned} \beta_k & \sim \text{Uniform}(-\infty, +\infty), k = 0, \dots, p \\ \log\sigma^2 & \sim \text{Uniform}(-\infty, +\infty) \end{aligned} \]
我們以後還會仔細再討論先驗概率分布的選擇問題。
99.2 Children in the Gambia
這個數據實例我們在簡單線性回歸的課程中(Chapter 27.6)也用過,它收集的是岡比亞農村兒童的身高體重年齡等信息。你可以有空和當時的模型擬合過程進行一個對比。這裏用到的變量是190名兒童的體重,年齡,和性別。圖 99.2示意的是這些兒童的體重和年齡及性別的關系。
## # A tibble: 6 × 4
## sex age wt len
## <dbl+lbl> <dbl> <dbl> <dbl>
## 1 2 [female] 23 8.40 73.2
## 2 2 [female] 22 10.9 84.4
## 3 2 [female] 6 7.20 68.7
## 4 1 [male] 24 10.3 83.7
## 5 1 [male] 14 10.5 79.2
## 6 2 [female] 18 9.60 75.8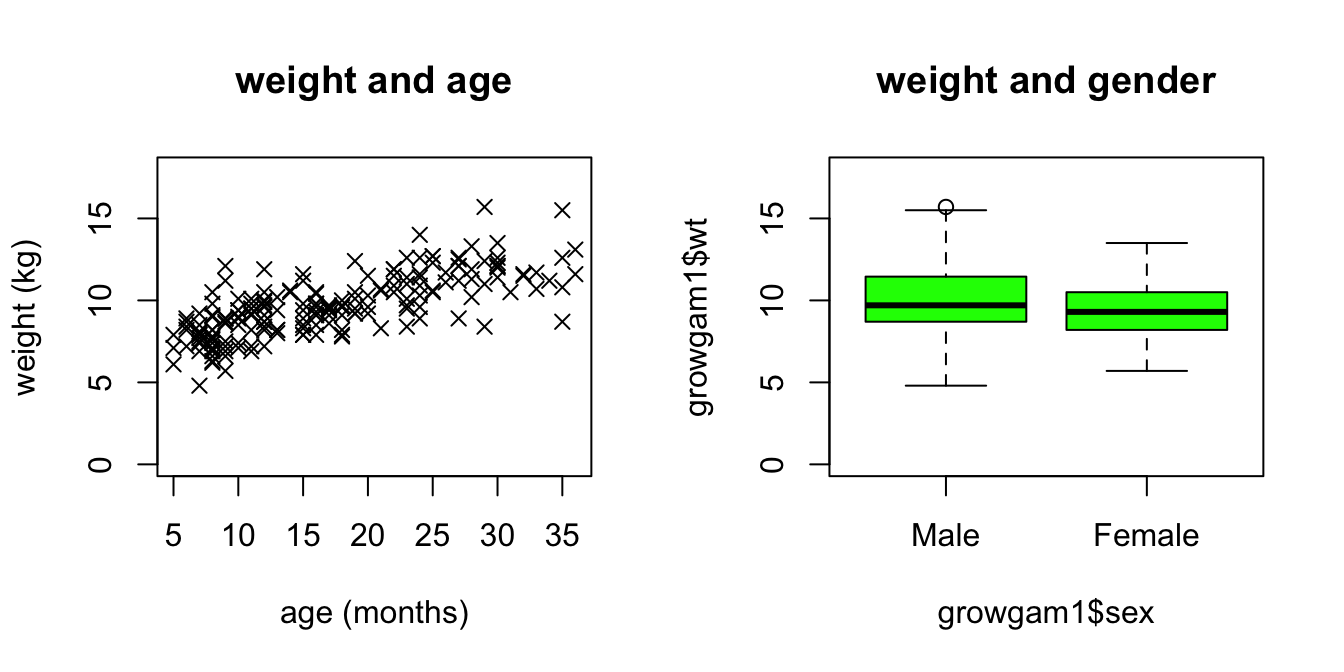
圖 99.2: Children in the Gambian cross-sectional survey
在這項橫斷面研究中,我們關心的主要是:
- 年齡每增加一個月,體重的變化是多少 kg?
- 男孩女孩之間的體重差別是多少 kg?
99.2.1 岡比亞兒童數據模型
我們給出的模型是:
- 結果變量 (outcome/response):體重(kg), weight in kg;
- 預測變量 (predictors):年齡(age in months),性別(1=男孩,2=女孩)。
一開始,我們的假設是,體重和年齡之間有線性關系(linear relationship),且誤差項服從正態分布。這一句話用貝葉斯統計學標記來表達就是:
\[ \begin{aligned} \text{wt}_i & \sim \text{Normal}(\mu_i, \sigma^2) \;\; i = 1, \dots, 190 \\ \mu_i & = \alpha + \beta \times \text{age}_i + \gamma \times \text{sex}_i \\ \log\sigma^2 & \sim \text{Uniform}(-100, 100) \\ \alpha & \sim \text{Uniform}(-1000, 1000) \\ \beta & \sim \text{Uniform}(-1000, 1000) \\ \gamma & \sim \text{Uniform}(-1000, 1000) \\ \end{aligned} \tag{99.1} \]
如果想用有向無環圖(DAG)來表示這個模型的話,可以用圖 99.3 來表示這個線性回歸模型。圖中每一個元素都用圓形或者方形來表示,各個成分之間的關系則用帶方向箭頭的直線或虛線來連接。大的方形標注着 Child \(i\) 的部分把該模型中被循環重復的部分。這個方形又被叫做盤(plates),盤內標記的名稱和下標表示每一個被循環重復的最小個體單位。在這個岡比亞兒童數據中,兩個共變量/預測變量(\(age_i, sex_i\)),和一個結果變量(\(wt_i\))是從每一名兒童身上測量獲得的,所以每一名兒童是模型循環重復的最小單位。未知參數 \(\alpha, \beta, \gamma, \sigma^2\) 都放在了盤以外的位置表示這些變量並不會隨着循環重復而改變。
值得注意的是,這個DAG圖 99.3 中有兩種不同類型的直線。如果在你寫下的模型(99.1)中兩個變量之間使用的是 \(\sim\) 連接的,那麼它們之間的連線就是實線,如果變量之間的關系使用的是等號 \(=\) 建立的關系,那麼它們之間的連線是虛線。因爲 \(\sim\) 表示的是隨機的不確定的關系(如服從某個先驗概率分布, stochastic links to a probability relationship),而等號 \(=\) 代表的關系是確定的 (deteministic relationships)。習慣上,圓形變量表示未知參數/隨機變量(random variables),方形變量表示觀測到的值(fully observed covariates)。盡管結果變量 \((wt_i)\) 是我們觀測收集的數據之一,但是在模型中它是隨機變量,因此在DAG繪圖法中也用圓形來標記。
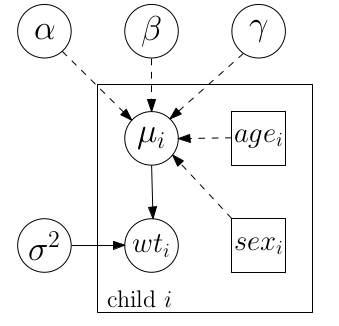
圖 99.3: DAG for Gambia Regression Model
99.2.2 BUGS model for Gambia example
模型的數學標記(表達式 (99.1))確定了以後,把它翻譯成BUGS語言就是下一步的工作了。本例中,我們並不想給模型加入任何有意義的先驗概率分布信息,所以給每個未知參數的先驗概率分布都是沒有信息的扁平的分布 (flat priors)。翻譯成BUGS語言以後的模型寫作:
model{
for(i in 1:190){ # loop through the 190 children
wt[i] ~ dnorm(mu[i], tau)
mu[i] <- alpha + beta*age[i] + gamma*sex[i]
}
# priors
alpha ~ dunif(-1000, 1000)
beta ~ dunif(-1000, 1000)
gamma ~ dunif(-1000, 1000)
logsigma2 ~ dunif(-100, 100)
sigma2 <- exp(logsigma2)
tau <- 1/sigma2
}99.2.3 Data file for the Gambia example
準備數據時,有兩種格式是適用的:
99.2.3.1 方形數據格式 rectangular format
sex[] age[] wt[]
2 23 8.40
2 22 10.9
2 6 7.20
1 24 10.3
1 14 10.5
2 18 9.60
...
1 30 12.1
END
99.2.3.2 R/S-plus 格式數據
這種格式的數據較爲靈活,你可以在其中放入長度不一樣的向量,假如我們在模型的第一行不給出兒童的人數 \(190\) 而是寫作:
for(i in 1:N){ # loop through the 190 children的話,那麼在數據文件中我們需要給出這個 N 的大小:
list(
N = 190,
wt = c(8.4, 10.9, , 7.2, 10.3, 10.5, ..., 12.1),
age = c(23, 22, 6, 24, 14, 18, ... , 30),
sex = c(2, 2, 2, 1, 1, 2, 2, ..., 1)
)99.2.4 初始值文件 initial value files
前一章節我們探討過如何確認事後概率分布的MCMC採樣達到收斂,其中一個要點是使用兩個或更多的起始值,前提是你給模型的未知參數起始值需要是在合理範圍內,且差異較大的起始值。同樣使用 list 命令。
MCMC採樣鏈1的起始值:
list(alpha = 0, beta = 1, gamma = 5, logsigma2 = 1)MCMC採樣鏈2的起始值:
list(alpha = 10, beta = 0, gamma = -5, logsigma2 = 5)99.2.5 給岡比亞兒童體重數據的貝葉斯模型檢查收斂 (MCMC check 1)
一開始我們先採集1000個事後概率分布樣本。模型中的四個未知參數\(\alpha, \beta, \gamma, \sigma^2\)的1000次事後MCMC採樣的歷史痕跡圖繪制如圖 99.4。我們可以看到模型收斂的速度很快。刨除前50次採樣的圖 (Fig. 99.5),可以對採樣過程看得更加清楚。像圖 99.5 這樣粗粗的有點像毛毛蟲一樣的歷史痕跡圖通常象徵已經達到理想的收斂。
# Read in the data:
Data <- read_tsv(paste(bugpath, "/backupfiles/gambia-data.txt", sep = ""))
# Data file for the model
Dat <- list(
N = nrow(Data),
wt = Data$wt,
age = Data$age,
sex = Data$sex
)
# initial values for the model
# the choice is arbitrary
inits <- list(
list(alpha = 0, beta = 1, gamma = 5, logsigma2 = 1),
list(alpha = 10, beta = 0, gamma = -5, logsigma2 = 5)
)
# fit the model in jags
jagsModel <- jags(data = Dat,
model.file = paste(bugpath,
"/backupfiles/gambia-model.txt",
sep = ""),
parameters.to.save = c("alpha", "beta", "gamma", "sigma2"),
n.iter = 2000,
n.chains = 2,
inits = inits,
progress.bar = "none")## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 190
## Unobserved stochastic nodes: 4
## Total graph size: 672
##
## Initializing model# Show the trace plot
Simulated <- coda::as.mcmc(jagsModel)
ggSample <- ggs(Simulated)
ggSample %>%
filter(Parameter %in% c("alpha", "beta", "gamma", "sigma2")) %>%
ggs_traceplot()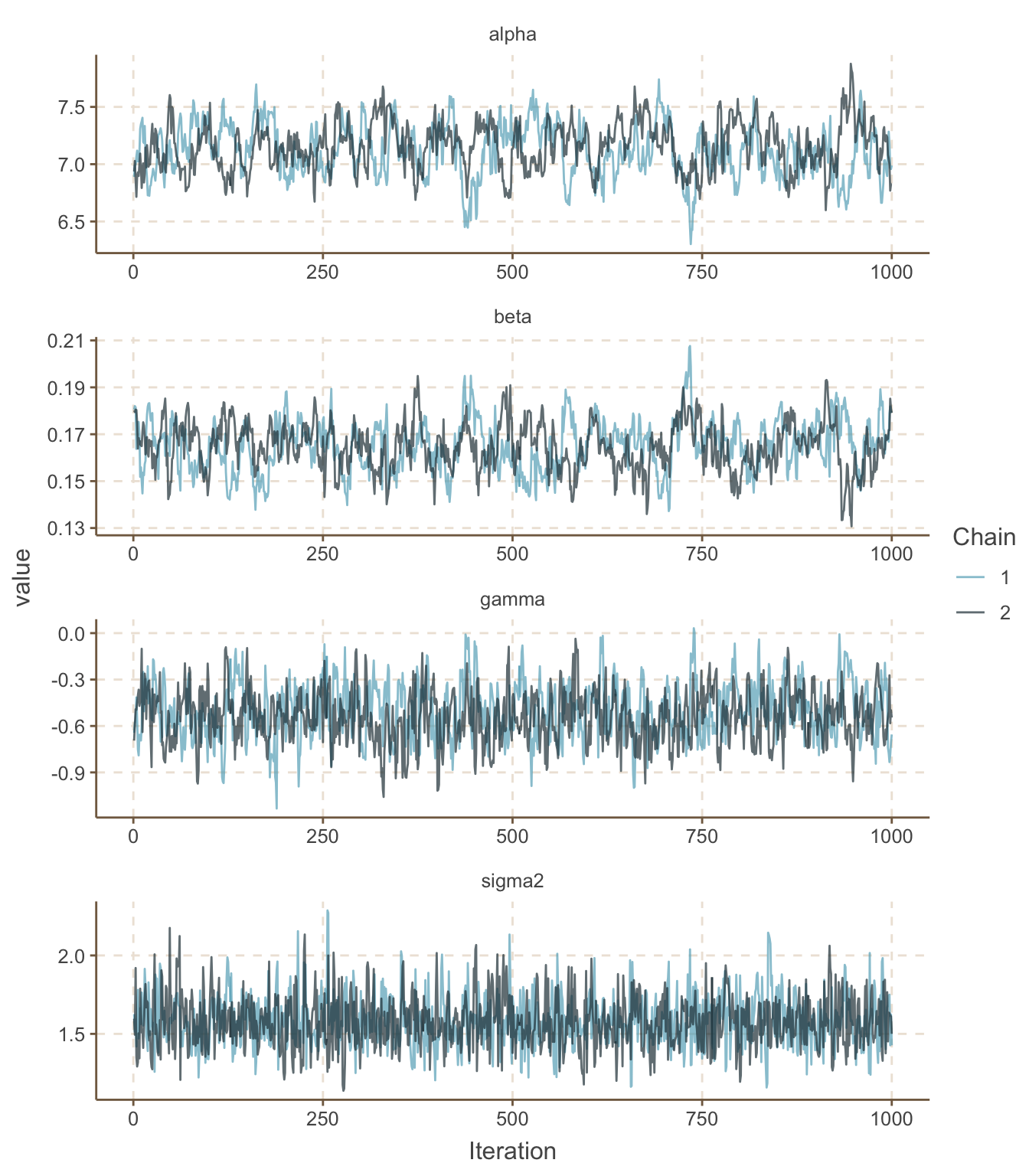
圖 99.4: History plots for iterations 1-1000 for the Gambia example.
ggSample %>%
filter(Iteration >= 51 & Parameter %in% c("alpha", "beta", "gamma", "sigma2")) %>%
ggs_traceplot()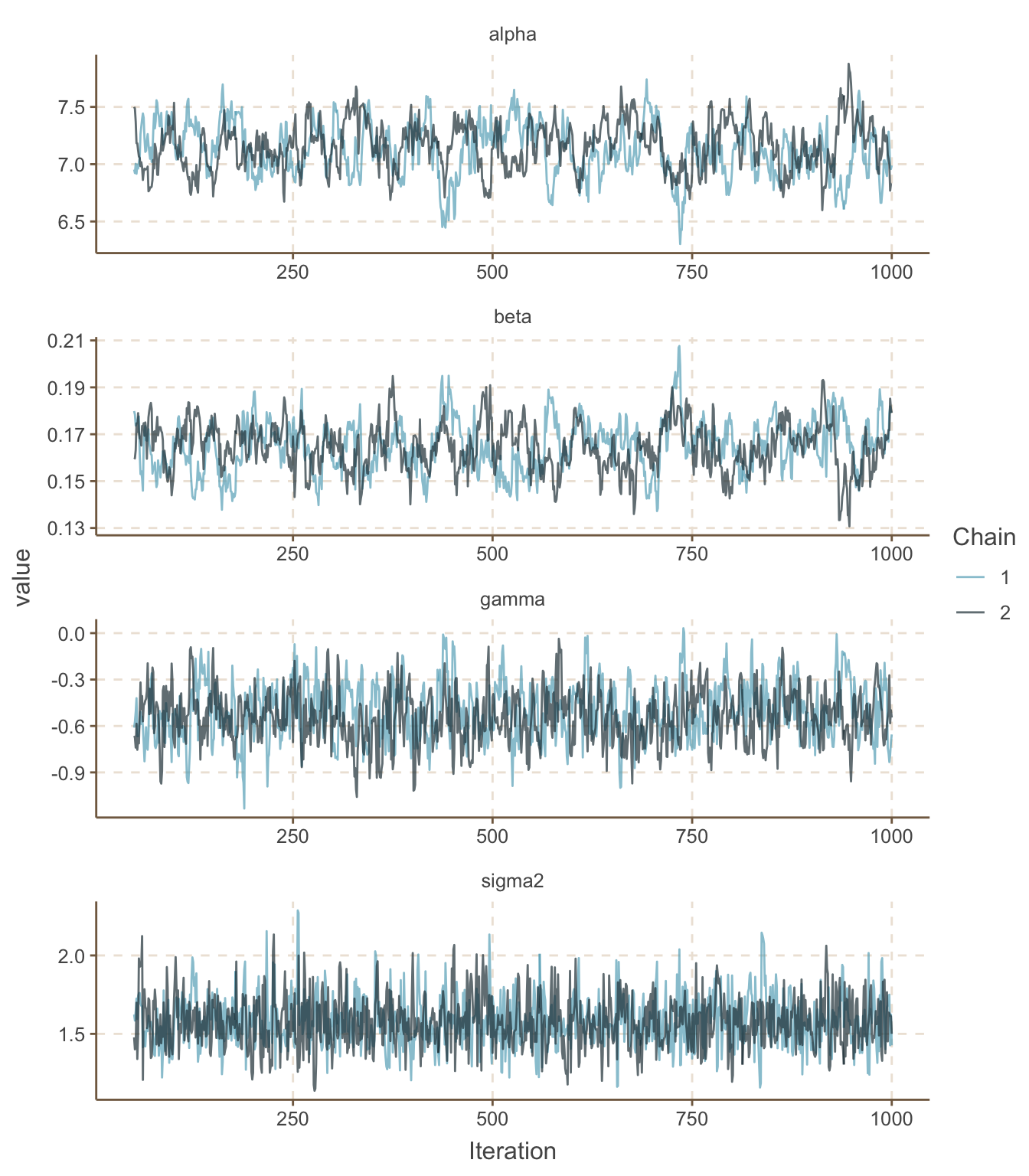
圖 99.5: History plots for iterations 51-1000 for the Gambia example.
再看這1000次MCMC抽樣獲得的 Gelman-Rubin 統計量,差不多鏈內鏈間差異的比值在1000次左右可以認爲等於1,所以我們把這前1000次MCMC採樣作爲 burn-in 從事後樣本中刨除。確定了 burn-in 之後我們再對每一條MCMC鏈重復採樣25000次。
## Potential scale reduction factors:
##
## Point est. Upper C.I.
## alpha 1.07 1.27
## beta 1.03 1.15
## deviance 1.05 1.12
## gamma 1.04 1.17
## sigma2 1.00 1.01
##
## Multivariate psrf
##
## 1.06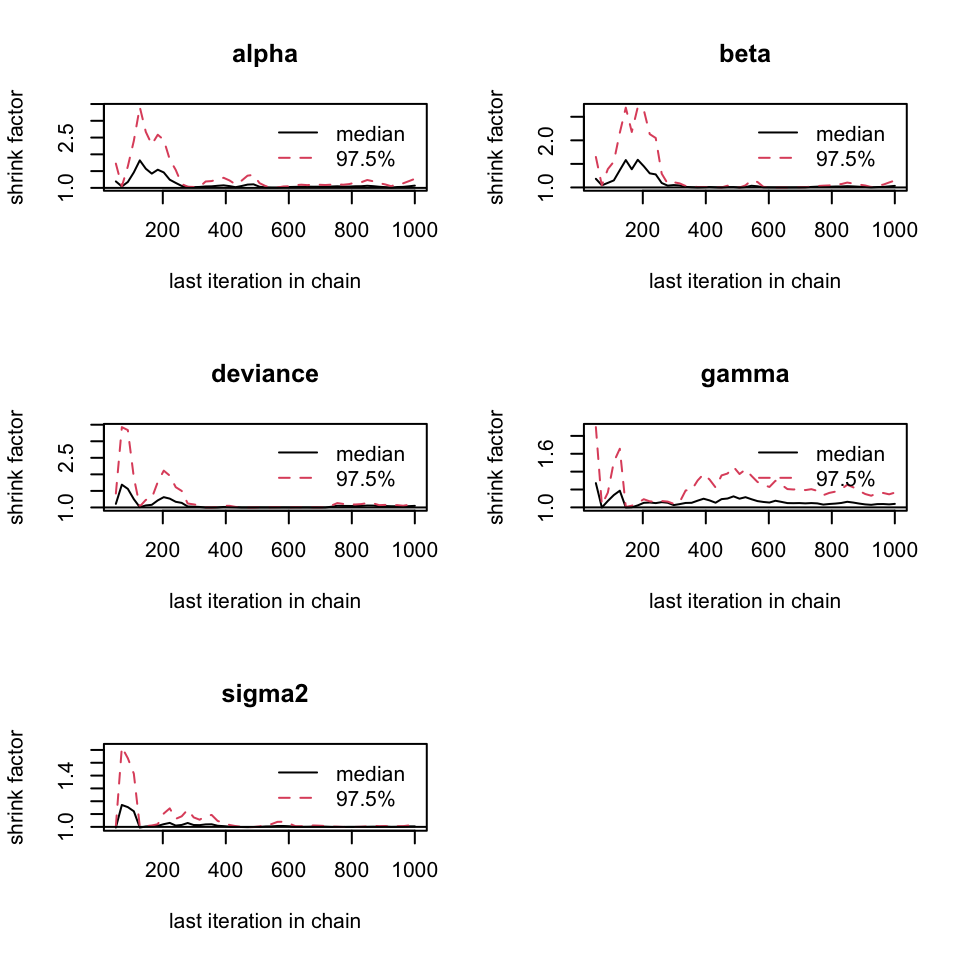
圖 99.6: Gelman-Rubin convergence statistic for the Gambia example.
99.2.6 岡比亞兒童體重數據的貝葉斯統計學推斷結果
# Generate 52000 iterations
jagsModel <- jags(data = Dat,
model.file = paste(bugpath,
"/backupfiles/gambia-model.txt",
sep = ""),
parameters.to.save = c("alpha", "beta", "gamma", "sigma2"),
n.iter = 26000,
n.chains = 2,
n.burnin = 1000,
inits = inits,
n.thin = 1,
progress.bar = "none")## module glm loaded## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 190
## Unobserved stochastic nodes: 4
## Total graph size: 672
##
## Initializing model##
## Iterations = 1:25000
## Thinning interval = 1
## Number of chains = 2
## Sample size per chain = 25000
##
## 1. Empirical mean and standard deviation for each variable,
## plus standard error of the mean:
##
## Mean SD Naive SE Time-series SE
## alpha 7.15525 0.236085 0.001055803 0.00440088
## beta 0.16385 0.010951 0.000048975 0.00019439
## deviance 625.14073 2.843174 0.012715062 0.02689234
## gamma -0.51940 0.185513 0.000829639 0.00202526
## sigma2 1.58017 0.166106 0.000742851 0.00098655
##
## 2. Quantiles for each variable:
##
## 2.5% 25% 50% 75% 97.5%
## alpha 6.69373 6.99473 7.15565 7.31404 7.61892
## beta 0.14221 0.15655 0.16381 0.17119 0.18517
## deviance 621.57606 623.04667 624.49813 626.54662 632.31463
## gamma -0.88195 -0.64499 -0.51853 -0.39354 -0.15994
## sigma2 1.28853 1.46310 1.56904 1.68383 1.93735由於我們給每個未知參數的先驗概率分布都是沒有實際信息的,因此,預期貝葉斯模型給出的結果將會十分接近概率論模型給出的分析結果,事實也證明的確是如此:
##
## Call:
## lm(formula = wt ~ age + factor(sex), data = growgam1)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.19236 -0.76268 -0.00696 0.75675 3.79163
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 7.152414 0.234254 30.5327 < 2.2e-16 ***
## age 0.163998 0.010919 15.0189 < 2.2e-16 ***
## factor(sex)2 -0.518854 0.183053 -2.8344 0.005095 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.2503 on 187 degrees of freedom
## Multiple R-squared: 0.5597, Adjusted R-squared: 0.55499
## F-statistic: 118.85 on 2 and 187 DF, p-value: < 2.22e-16##
## Coeff lower095ci upper095ci Pr>|t|
## (Intercept) 7.15241353 6.69029297 7.61453409 1.4039052e-74
## age 0.16399839 0.14245724 0.18553954 5.7949167e-34
## factor(sex)2 -0.51885399 -0.87996857 -0.15773941 5.0951539e-03即使用 Stata 獲得的也是一樣的結果,差異十分微小。
##
## . use "../backupfiles/growgam1.dta"
##
## . regress wt age i.sex
##
## Source | SS df MS Number of obs = 190
## -------------+---------------------------------- F(2, 187) = 118.85
## Model | 371.623281 2 185.81164 Prob > F = 0.0000
## Residual | 292.346478 187 1.56335015 R-squared = 0.5597
## -------------+---------------------------------- Adj R-squared = 0.5550
## Total | 663.969759 189 3.51306751 Root MSE = 1.2503
##
## ------------------------------------------------------------------------------
## wt | Coef. Std. Err. t P>|t| [95% Conf. Interval]
## -------------+----------------------------------------------------------------
## age | .1639984 .0109195 15.02 0.000 .1424572 .1855395
## |
## sex |
## female | -.518854 .1830531 -2.83 0.005 -.8799686 -.1577394
## _cons | 7.152414 .2342542 30.53 0.000 6.690293 7.614534
## ------------------------------------------------------------------------------
##
## .99.2.7 檢查岡比亞兒童體重數據貝葉斯模型的有效樣本量 effective sample size (MCMC check 2)
盡管我們獲取了50000個事後MCMC樣本,但是關於 \(\text{MC_error} \approx 2 \text{ orders of magnitude smaller than the posterior SD}\) 的經驗法則 (rule of thumb),其實並沒有得到滿足。實際用於估計事後 \(\alpha, \beta\) 的有效樣本量是小於 10000的。繪制每個參數的自回歸 (autocorrelation) 圖也證實了這些事後樣本有許多有強的自相關:
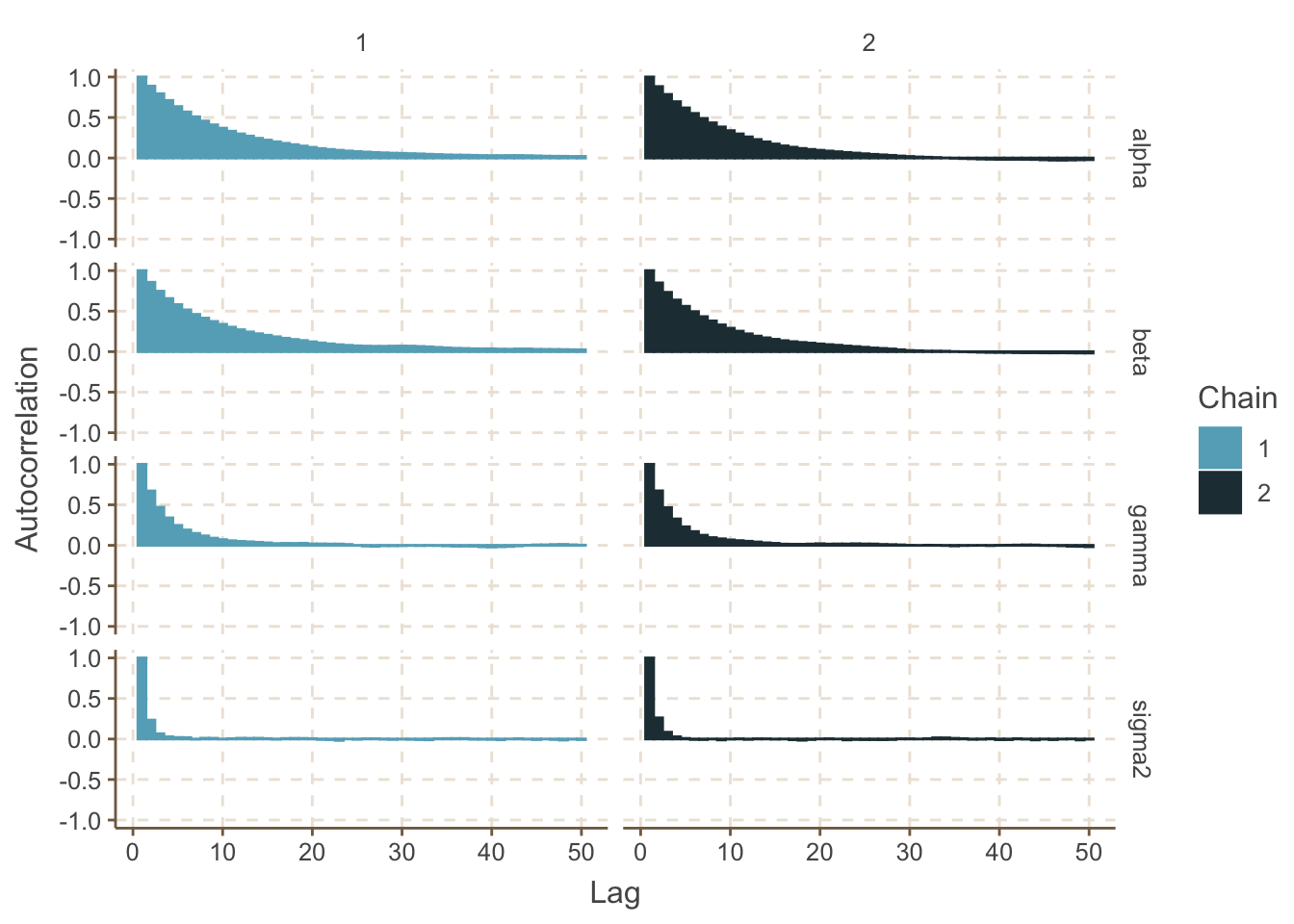
圖 99.7: Autocorrelation plot for the Gambia example (uncentered model, chain 1-2)
這些 MCMC 樣本的自相關程度之所以如此之高,其最主要的原因是我們沒有把連續變量年齡給中心化。解決這個問題的辦法是把原先模型中的線性回歸模型的年齡變量給中心化:
mu[i] <- alpha + beta*(age[i] - mean(age[])) + gamma*sex[i]這一次我們獲得的50000個MCMC事後樣本的參數估計結果如下:
# Generate 51000 iterations
jagsModel <- jags(data = Dat,
model.file = paste(bugpath,
"/backupfiles/gambia-model-agecen.txt",
sep = ""),
parameters.to.save = c("alpha", "beta", "gamma", "sigma2"),
n.iter = 26000,
n.chains = 2,
n.burnin = 1000,
inits = inits,
n.thin = 1,
progress.bar = "none")## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 190
## Unobserved stochastic nodes: 4
## Total graph size: 706
##
## Initializing model##
## Iterations = 1:25000
## Thinning interval = 1
## Number of chains = 2
## Sample size per chain = 25000
##
## 1. Empirical mean and standard deviation for each variable,
## plus standard error of the mean:
##
## Mean SD Naive SE Time-series SE
## alpha 9.93477 0.138269 0.000618358 0.001467596
## beta 0.16400 0.010905 0.000048768 0.000063547
## deviance 625.07272 2.835241 0.012679581 0.021955846
## gamma -0.51668 0.183846 0.000822185 0.001930376
## sigma2 1.58092 0.162130 0.000725069 0.000954518
##
## 2. Quantiles for each variable:
##
## 2.5% 25% 50% 75% 97.5%
## alpha 9.66463 9.84081 9.93538 10.02775 10.20531
## beta 0.14258 0.15667 0.16401 0.17130 0.18532
## deviance 621.54636 622.99966 624.41405 626.46184 632.16316
## gamma -0.87797 -0.64005 -0.51696 -0.39468 -0.15594
## sigma2 1.29418 1.46782 1.57031 1.68345 1.92450## Inference for Bugs model at "/Users/chaoimacmini/Downloads/LSHTMlearningnote/backupfiles/gambia-model-agecen.txt", fit using jags,
## 2 chains, each with 26000 iterations (first 1000 discarded)
## n.sims = 50000 iterations saved
## mu.vect sd.vect 2.5% 25% 50% 75% 97.5% Rhat n.eff
## alpha 9.935 0.138 9.665 9.841 9.935 10.028 10.205 1.001 36000
## beta 0.164 0.011 0.143 0.157 0.164 0.171 0.185 1.001 50000
## gamma -0.517 0.184 -0.878 -0.640 -0.517 -0.395 -0.156 1.001 19000
## sigma2 1.581 0.162 1.294 1.468 1.570 1.683 1.924 1.001 27000
## deviance 625.073 2.835 621.546 623.000 624.414 626.462 632.163 1.001 25000
##
## For each parameter, n.eff is a crude measure of effective sample size,
## and Rhat is the potential scale reduction factor (at convergence, Rhat=1).
##
## DIC info (using the rule, pD = var(deviance)/2)
## pD = 4.0 and DIC = 629.1
## DIC is an estimate of expected predictive error (lower deviance is better).注意到這時候事後參數估計給出的 alpha 結果發生了微妙的變化,然而其他的幾個變量的事後估計結果幾乎沒有改變。且此時 MC_error 也變得小了很多,達到了我們的經驗法則所要求的。這時候的事後MCMC採樣鏈的自相關圖也提供較爲了理想的結果:
Simulated <- coda::as.mcmc(jagsModel)
ggSample <- ggs(Simulated)
ggSample %>%
filter(Parameter %in% c("alpha", "beta", "gamma", "sigma2")) %>%
ggs_autocorrelation()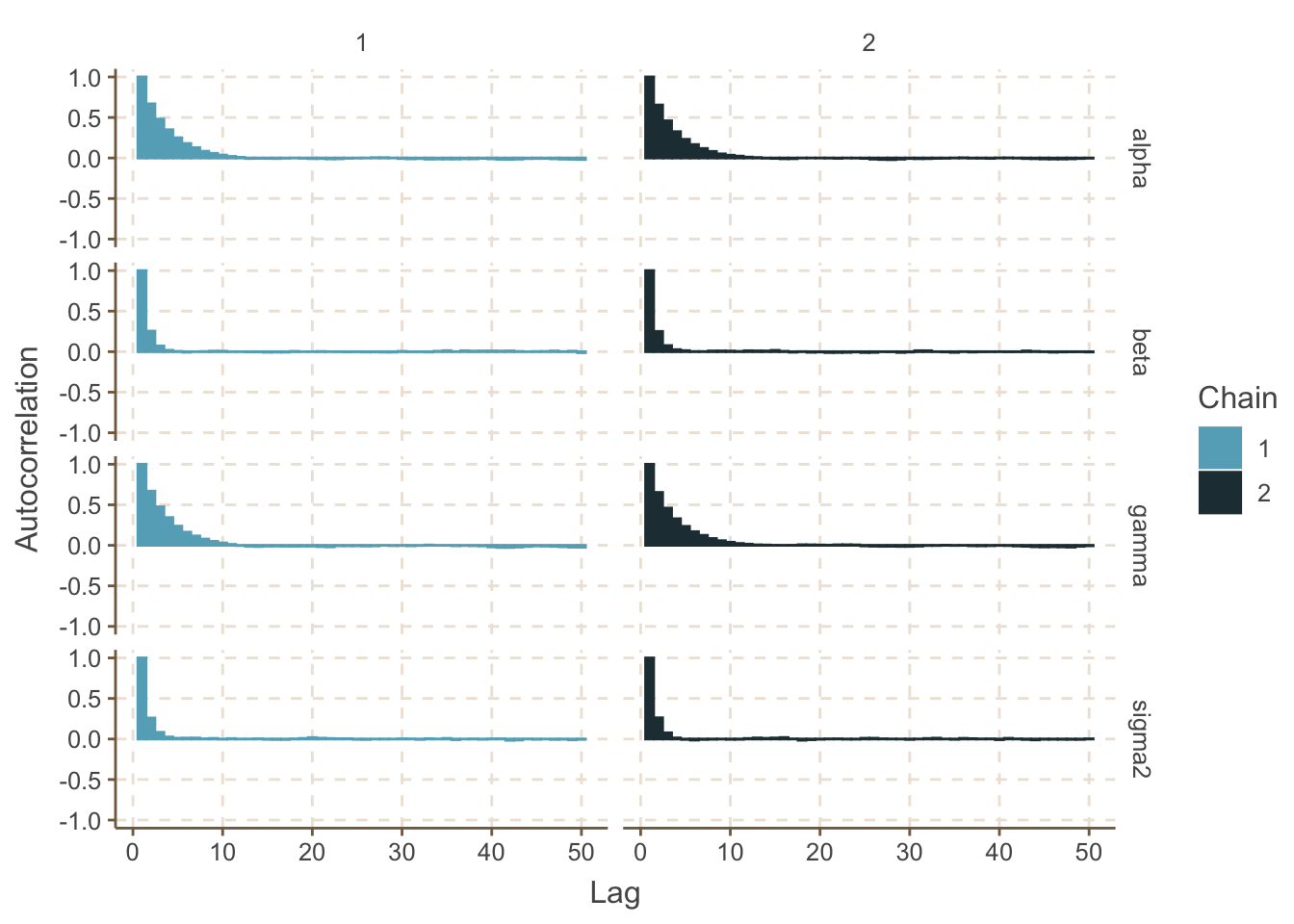
圖 99.8: Autocorrelation plot for the Gambia example (centered model, chain 1)
共變量年齡,和性別的回歸系數的事後概率分布圖繪制如下:
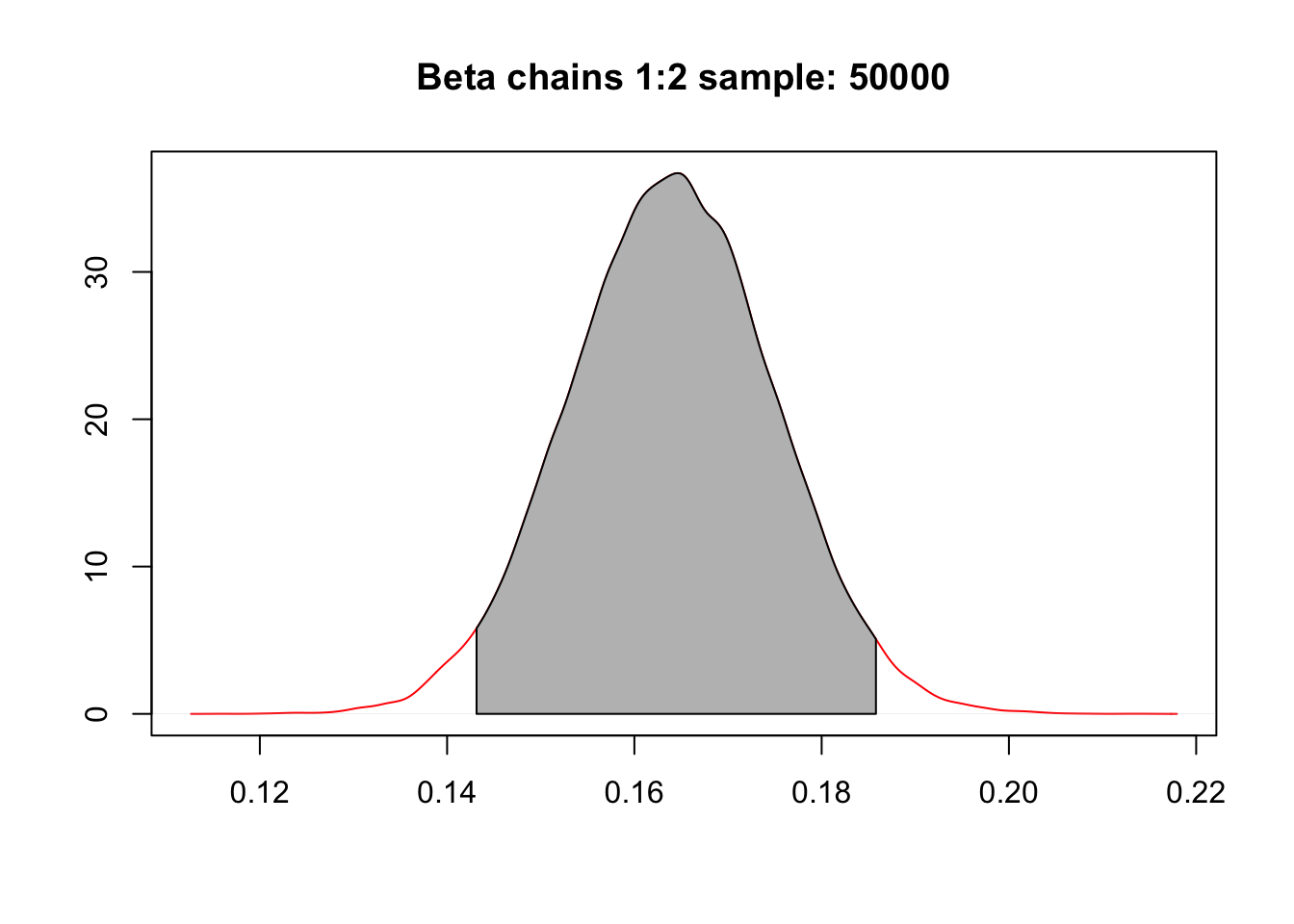
圖 99.9: Change in weight per month increase in age (posterior mean: 0.164 kg, 95% credible interval (0.143, 0.186)
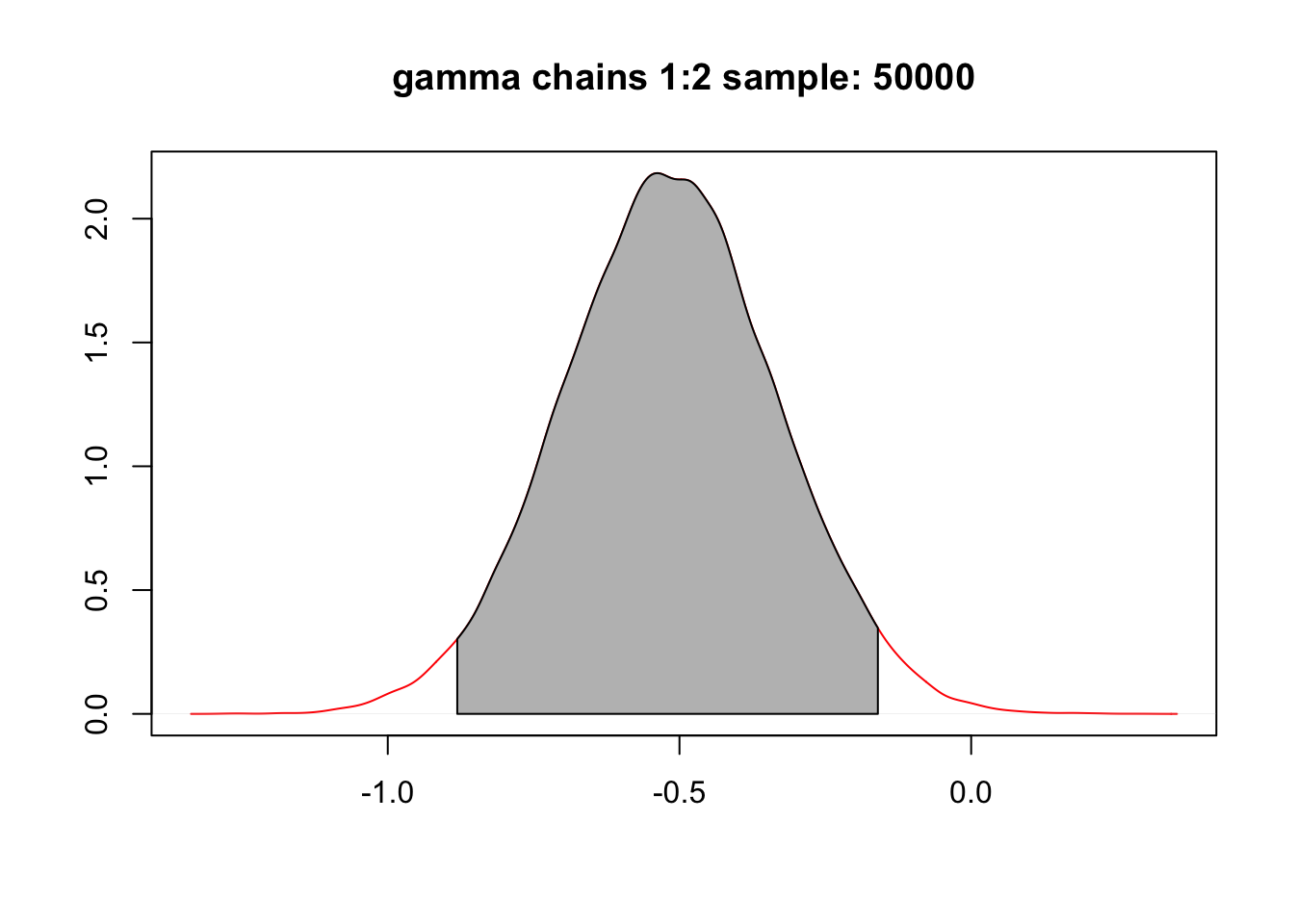
圖 99.10: Change in weight for girls compared to boys (posterior mean: -0.520 kg, 95% credible interval (-0.880, -0.160)
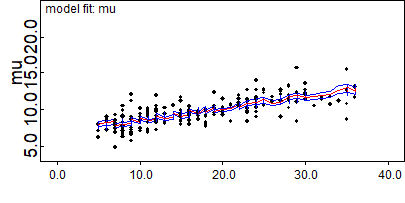
圖 99.11: Fitted regression line versus covariate (age)
BUGS軟件也能提供類似圖 99.11 這樣的擬合值和共變量年齡之間的關系的圖。其中紅色線代表體重的擬合值,藍色線代表95%可信區間的範圍。
經過這些步驟的分析,相信你也意識到,給貝葉斯模型中的共變量中心化(centering covariates),是提高模型分析採樣效率的好方法。它把事後未知參數的位置中心化,同時減少事後MCMC採樣的自相關。之前沒有把年齡中心化的模型結果也提示我們如果共變量未被中心化,其事後概率分布的MCMC樣本的有效樣本量是會被打了折扣的,採樣的收斂速度也較長。
99.2.8 檢查模型擬合程度 checking model fit for the Gambia example
目前爲止我們完成了貝葉斯簡單線性回歸模型的建立,及其事後概率樣本的 MCMC 採集。下一步應該做的是對模型的擬合度進行檢查。模型檢查包括我們在簡單先行回顧章節學習過的一些標準(standard)檢查要點:
- 殘差 residuals:把殘差和各個共變量做散點圖,檢查每個未知參數的自相關;
- 預測 prediction:把創建的模型拿到其他的新數據中驗證其外部有效程度 (external validation/cross validation)。
除此之外,我們仍然要補充做的包括:
- 檢查先驗概率分布和實際觀察數據之間是否有衝突 check for conflict between prior and data;
- 檢查貝葉斯模型是否會對不同的先驗概率分布較爲敏感 check for unintended sensitivity to the prior。
標準化殘差 (standardised residuals) 的計算公式是 \(r = \frac{y - \mu}{\sigma}\),其中 \(\mu = E[y], \sigma^2 = V[y]\)。在貝葉斯模型中獲得的殘差也是隨機變量 (random quantities),有自己的分布。如果你願意,你可以把殘差的事後概率分布密度圖給繪制出來,或者選擇檢驗分布的形狀參數 (testing distributional shape)等等方法來檢驗殘差,但是如果你只要給每個對象提取一個模型殘差值,你的選擇可以有:
- 標準化殘差的事後概率分布均值 posterior mean of the standardised residuals \(E(r)\);
- (plug-in posterior mean) 或者把參數的事後均值\(\mu\)及其標準差\(\sigma\)的均值放到計算式裏面: \(r = \frac{y - E(\mu)}{E(\sigma)}\)。
使用MCMC計算機模擬試驗的算法優勢,我們擁有了重復計算大量參數的能力。所以對於每一個觀察對象(岡比亞兒童),我們可以用這個線性回歸模型計算他/她的體重的事後預測分布(predictive distribution) \(y_i^{pred}\),然後把他/她的體重觀察值\((y_i^{obs})\)和他/她的體重事後概率分布做比較。利用 step 命令來計算每個孩子身上用模型計算的預測體重分布中,小於觀察的體重數據的面積 \(p(y_i^{pred} < y_i^{obs})\)。如果有許多觀測值,位於它各自事後概率分布的兩極(即預測體重遠小於,或者遠大於觀測體重),那麼可以認爲該模型擬合度較差。
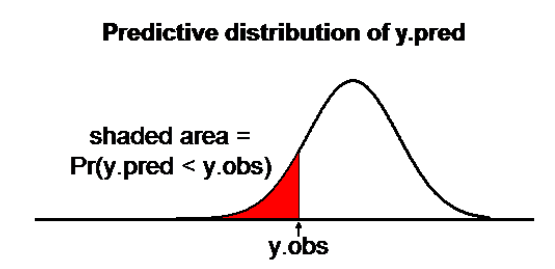
圖 99.12: Predictive check
用岡比亞兒童體重的貝葉斯模型來說,我們利用MCMC強大的事後樣本採集能力,在模型中增加並監測三個新的變量 res, wt.pred, p.pred:
model{
for(i in 1:190){ # loop through the 190 children
wt[i] ~ dnorm(mu[i], tau)
mu[i] <- alpha + beta*(age[i] - mean(age[])) + gamma*sex[i]
# standardised residuals
res[i] <- (wt[i] - mu[i]) / sqrt(sigma2)
# predictions
wt.pred[i] ~ dnorm(mu[i], tau) # repredict for each child
p.pred[i] <- step(wt[i] - wt.pred[i])
}
# priors
alpha ~ dunif(-1000, 1000)
beta ~ dunif(-1000, 1000)
gamma ~ dunif(-1000, 1000)
logsigma2 ~ dunif(-100, 100)
sigma2 <- exp(logsigma2)
tau <- 1/sigma2
}所以我們只要增加對新增的三個變量 res, wt.pred, p.pred 的事後樣本採集的監控就可以了。圖 99.13 展示了BUGS軟件提供的殘差分析圖(caterpillar/毛蟲 plot)。它其實十分接近箱式圖 (box-plot),唯一的區別是不顯示四分位數間距 (inter-quartile range)。毛蟲圖的最大優點在於,便於比較有很多事後概率分布的情況,像本例中190名兒童的體重都有各自的事後概率分布,他們每人的殘差也有各自的分布。圖 99.14 則是BUGS軟件繪制的岡比亞兒童體重的95%預測區間,後面的黑色散點圖是觀察值。
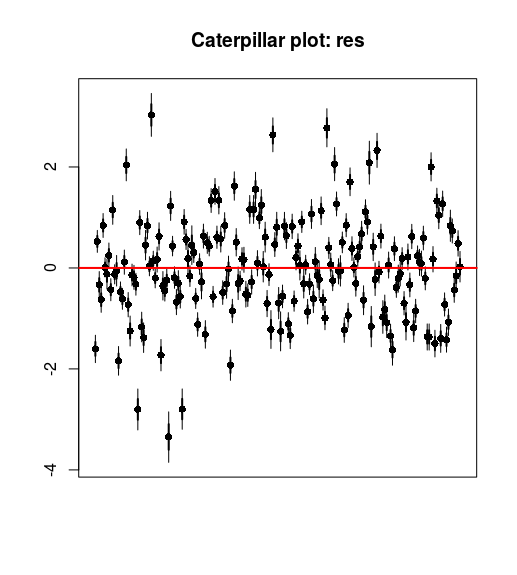
圖 99.13: Caterpillar plot of the posterior distribution of standardised residuals vs. child ID
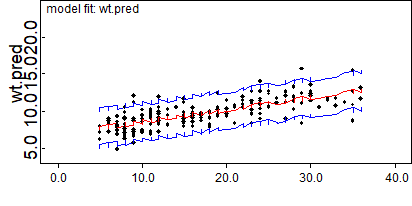
圖 99.14: Prediction bands for replicate data.
99.2.9 其他的替代模型 alternative model with t-errors
檢查一個模型意爲着我們可能需要替代模型。例如,我們可以使模型中的體重不是服從正態分布,而是服從 t 分布,因爲 t 分布將會給模型提供更高的穩健性。(t分布的兩端面積比起正態分布要大一些,也就是允許模型考慮更多的離羣值outliers):
model{
for(i in 1:190){ # loop through the 190 children
wt[i] ~ dt(mu[i], tau, 4) # robust likelihood t distribution on 4 df
mu[i] <- alpha + beta*(age[i] - mean(age[])) + gamma*sex[i]
}
# priors
alpha ~ dunif(-1000, 1000)
beta ~ dunif(-1000, 1000)
gamma ~ dunif(-1000, 1000)
logsigma2 ~ dunif(-100, 100)
sigma2 <- exp(logsigma2)
tau <- 1/sigma2
}99.3 貝葉斯統計模型的比較 Bayesian model comparison
在使用統計學模型時,我們自然而然地想用模型對數據的擬合度來輔助進行模型的篩選及比較。常用的指標有 Akaike Information Criterion (AIC):
\[ \text{AIC} = -2\log p(y | \hat \theta) + 2k \] 其中, \(p(y|\hat\theta)\) 就是模型的似然(likelihood)用來代表模型對數據的擬合度,\(k\) 是模型中的未知參數個數,用來表示模型的復雜程度。
99.3.1 Deviance Information Criterion (DIC)
(Spiegelhalter et al. 2002)提出用 DIC 來比較貝葉斯模型。它也是利用和 AIC 類似的思想,使用DIC來綜合表示模型的擬合度,及模型的復雜程度:
\[ \text{DIC} = \text{goodness of fit} + \text{complexity} \]
其中模型的擬合程度部分用的是模型偏差值:\(D(\theta) = -2\log L(data | \theta)\);
模型復雜程度使用的則是,模型中有效的未知參數的個數:
\[ \begin{aligned} p_D & = E_{\theta | y}[D] - D(E_{\theta | y}[\theta]) \\ & = \bar D - D(\bar\theta) \end{aligned} \]
i.e. the posterior mean deviance minus the deviance evaluated at the posterior mean of the parameters.
然後 DIC 的定義也模仿 AIC:
\[ \begin{aligned} \text{DIC} & = D(\bar\theta) + 2 p_D \\ & = \bar D + p_D \end{aligned} \]
比較的方法是DIC越小的模型,越優,數據越支持。
- 如果兩個模型的 DIC 相差大於 10,說明DIC較小的模型更好;
- 如果兩個模型的 DIC 相差小於 5,說明兩個模型無太大差別。
在BUGS軟件中你需要像追蹤監測其他隨機變量一樣監測模型的DIC,特別是要在確定模型已經達到收斂之後,採集收斂之後的 DIC 數值用於比較。
99.3.2 岡比亞兒童體重數據模型比較
當設定體重服從正態分布時,我們獲得模型的 DIC 是
Dbar Dhat DIC pD
wt 625.1 621.1 629.1 3.983
total 625.1 621.1 629.1 3.983當設定體重服從自由度爲4的t分布時,我們獲得模型的 DIC 是
Dbar Dhat DIC pD
wt 622.1 618 626.2 4.114
total 622.1 618 626.2 4.114兩個模型的DIC差別在3左右,也就是說用正態分布,或者t分布,對結果影響不大。
這兩個模型給出的我們的問題的答案也不會有本質上的差別:
- 年齡每增加1個月,體重的變化:
- 正態分布:\(\beta\) 的事後均值爲 0.164 kg,95% 可信區間 (0.143, 0.186);
- t 分布:\(\beta\) 的事後均值爲 0.167 kg, 95% 可信區間 (0.146, 0.187)。
- 男孩和女孩的體重差別:
- 正態分布:\(\gamma\) 的事後均值爲 -0.520 kg,95% 可信區間 (-0.880, -0.160);
- t 分布:\(\gamma\) 的事後均值爲 -0.574 kg,95% 可信區間 (-0.915, -0.232)。
99.4 Practical Bayesian Statistics 05
本次練習我們來比較多個貝葉斯線性回歸模型。看看在模型中增加其他的變量是否能改善模型的擬合度,最終你會選哪個線性回歸模型來回答一開始我們提出的問題。
除了本章實例中使用的線性回歸模型,另外可以拿來比較的模型分別是:
- 增加年齡的二次方項 \(age^2\);
- 增加年齡和性別的交互作用項 \(age \times sex\)。
在思考貝葉斯模型怎樣增加上面兩個變量的語法的同時,請思考這樣幾個問題:
- 要怎樣修改模型的BUGS代碼才能正確表達想要增加的模型變量?特別是模型應該怎麼寫才能把年齡的平方中心化?
- 如何寫MCMC鏈的起始值?
- 跑完模型以後,給模型的擬合實施常規的檢查。
- 簡單線性迴歸模型中增加了這些部分後的結果,要如何回答我們一開始提出的問題?(年齡每增加一個月,體重的變化是多少kg?男孩和女孩之間的體重差別是多少kg?)
99.4.1 增加年齡二次方項 adding age squared
model{
for(i in 1:190){ # loop through the 190 children
wt[i] ~ dnorm(mu[i], tau)
mu[i] <- alpha + beta*cage[i] + gamma*sex[i] + delta*cagesq[i]
cage[i] <- age[i] - mean(age[]) # centered age
agesq[i] <- pow(age[i], 2)
cagesq[i] <- agesq[i] - mean(agesq[]) # centered age squared
# standardised residuals
res[i] <- (wt[i] - mu[i]) / sqrt(sigma2)
# predictions
wt.pred[i] ~ dnorm(mu[i], tau) # repredict for each child
p.pred[i] <- step(wt[i] - wt.pred[i])
}
# priors
alpha ~ dunif(-1000, 1000)
beta ~ dunif(-1000, 1000)
gamma ~ dunif(-1000, 1000)
delta ~ dunif(-1000, 1000)
logsigma2 ~ dunif(-100, 100)
sigma2 <- exp(logsigma2)
tau <- 1/sigma2
}使用的兩個MCMC鏈的起始值分別是:
initlist <- list(alpha = 0, beta = 1, gamma = 5, delta = -1, logsigma2 = 1)
initlist1 <- list(alpha = 10, beta = 0, gamma = -5, delta = 1, logsigma2 = 5)獲得的50000個事後概率分佈樣本的統計描述是:
mean sd MC_error val2.5pc median val97.5pc start sample
alpha 9.945000 0.136100 1.166e-03 9.677000 9.945000 10.2100000 1001 50000
beta 0.256600 0.053360 1.452e-03 0.151600 0.256500 0.3621000 1001 50000
delta -0.002429 0.001372 3.731e-05 -0.005133 -0.002422 0.0002715 1001 50000
gamma -0.535000 0.181100 1.526e-03 -0.887300 -0.534900 -0.1815000 1001 50000
sigma2 1.563000 0.164300 8.325e-04 1.275000 1.551000 1.9190000 1001 50000模型的 DIC 是:
Dbar Dhat DIC pD
wt 623 618 628 5.008
total 623 618 628 5.008和之前沒有增加年齡平方的模型相比較DIC減少了大概只有1。因此,基本沒有差別的情況下,我們選擇沒有年齡平方的一開始的模型。從 delta 的事後概率分佈結果也知道它的95%可信區間是包括0的。也說明了增加年齡平方項的部分無太多意義。
99.4.2 增加年齡和性別的交互作用項 adding an interaction term
model{
for(i in 1:190){ # loop through the 190 children
wt[i] ~ dnorm(mu[i], tau)
mu[i] <- alpha + beta*cage[i] + gamma*sex[i] + delta*cage[i]*sex[i]
cage[i] <- age[i] - mean(age[]) # centered age
# standardised residuals
res[i] <- (wt[i] - mu[i]) / sqrt(sigma2)
# predictions
wt.pred[i] ~ dnorm(mu[i], tau) # repredict for each child
p.pred[i] <- step(wt[i] - wt.pred[i])
}
# priors
alpha ~ dunif(-1000, 1000)
beta ~ dunif(-1000, 1000)
gamma ~ dunif(-1000, 1000)
delta ~ dunif(-1000, 1000)
logsigma2 ~ dunif(-100, 100)
sigma2 <- exp(logsigma2)
tau <- 1/sigma2
}使用的起始值分別是:
initlist <- list(alpha = 0, beta = 1, gamma = 5, delta = -5, logsigma2 = 1)
initlist1 <- list(alpha = 10, beta = 0, gamma = -5, delta = 5, logsigma2 = 5)事後概率分佈樣本的統計學描述是:
mean sd MC_error val2.5pc median val97.5pc start sample
alpha 9.937000 0.13730 0.0011460 9.66900 9.936000 10.21000 1001 50000
beta 0.165500 0.01609 0.0001244 0.13380 0.165500 0.19710 1001 50000
delta -0.002979 0.02223 0.0001703 -0.04668 -0.003053 0.04065 1001 50000
gamma -0.519900 0.18380 0.0015730 -0.88040 -0.518800 -0.16250 1001 50000
sigma2 1.590000 0.16700 0.0007803 1.29800 1.578000 1.94800 1001 50000DIC是:
Dbar Dhat DIC pD
wt 626.1 621.1 631.1 5.003
total 626.1 621.1 631.1 5.003增加了性別年齡交互項的模型給出的DIC比原先的模型大了2個單位左右,所以,我們還是會選擇沒有交互作用項的一開始的簡單線性迴歸模型。