第 15 章 假設檢驗的構建 Construction of a hypothesis test
15.1 什麼是假設檢驗 Hypothesis testing
一般來說,我們的假設(或者叫假說) 是對與我們實驗觀察數據來自的總體(或人羣) 的概率分佈的描述。在參數檢驗的背景下,就是要檢驗描述這個總體(或人羣) 的概率分佈的參數 (parameters)。最典型的情況是,我們提出兩個互補的假設,一個叫作零假設(或者叫原假設) ,null hypothesis (\(H_0\));另一個是與之對應的(互補的) 替代假設,althernative hypothesis (\(H_1/H_A\))。
例如,若 \(X\) 是一個服從二項分佈的隨機離散變量 \(X\sim Bin(5, \theta)\)。可以考慮如下的零假設和替代假設:\(H_0: \theta=\frac{1}{2}; H_1: \theta=\frac{2}{3}\)。
當建立了零假設和替代假設以後,假設檢驗就是要建立如下的規則以確定:
- 從樣本中計算所得的參數估計值爲多少時,拒絕零假設。(接受替代假設爲“真”)
- 從樣本中計算所得的參數估計值爲多少時,零假設不被拒絕。(接受零假設爲“真”)
注意:(這一段很繞)
上面的例子是零假設和替代假設均爲簡單假設的情況,實際操作中常常會設計更加複雜的(不對稱的) 假設:即簡單的 \(H_0\),複雜的 \(H_1\)。如此一來當零假設 \(H_0\) 不被拒絕時,我們並不一定就接受之。因爲無證據證明 \(H_1\) 不等於有證據證明 \(H_0\)。(Absence of evidence is not evidence of absence). 換句話說,無證據讓我們拒絕 \(H_0\) 本身並不成爲支持 \(H_0\) 爲“真”的證據。因爲在實際操作中,當我們設定的簡單的零假設沒有被拒絕,可能還存在其他符合樣本數據的零假設;相反地,當樣本數據的計算結果拒絕了零假設,我們只能接受替代假設。所以,反對零假設的證據,同時就是支持替代假設的證據。
在樣本空間 sample space 中,決定了零假設 \(H_0\) 會被拒絕的子集 subset,被命名爲拒絕域 rejection region 或者 判別區域 critical region,用 \(\mathfrak{R}\) 來標記。
15.2 錯誤概率和效能方程 error probabilities and the power function
這一部分也可以參考本書臨牀試驗樣本量計算 (Section 34) 部分。
| \(\underline{x} \notin \mathfrak{R}\) Accept \(H_0\) | \(\underline{x} \in \mathfrak{R}\) Reject \(H_0\) | ||
|---|---|---|---|
| TRUTH | \(H_0\) is true | \(\checkmark\) |
\(\alpha\) Type I error |
| \(H_1\) is true |
\(\beta\) Type II error |
\(\checkmark\) |
假如一個假設檢驗是關於總體參數 \(\theta\) 的:
\[H_0: \theta=\theta_0 \text{ v.s. } H_1: \theta=\theta_1 \]
這個檢驗的效能被定義爲當替代假設爲“真”時,拒絕零假設的概率(該檢驗方法能夠檢驗出有真實差別的能力) :
\[\text{Power}=\text{Prob}(\underline{x}\in\mathfrak{R}|H_1\text{ is true}) = 1-\text{Prob}(\text{Type II error})\]
觀察數據只有兩種可能:落在拒絕域內,或者落在拒絕域之外。第二類錯誤我們常常使用 \(\beta\) 來表示,所以 \(\text{Power}=1-\beta\)。
檢驗的顯著性水平用 \(\alpha\) 來表示。\(\alpha\) 的直觀意義就是,檢驗結果錯誤的拒絕了零假設 \(H_0\),接受了替代假設 \(H_1\),即假陽性的概率。
\[\text{Prob}(\underline{x}\in \mathfrak{R} |H_0 \text{ is true})=\text{Prob(Type I error)}\]
15.2.1 以二項分佈爲例
用本文開頭的例子: \(X\sim Bin(5,\theta)\)。和我們建立的零假設和替代假設:\(H_0: \theta=\frac{1}{2}; H_1: \theta=\frac{2}{3}\):
考慮兩種檢驗方法:
- A 方法:當且僅當5次觀察都爲“成功”時才拒絕 \(H_0 (\text{i.e.}\; X=5)\)。所以此時判別區域 \(\mathfrak{R}\) 爲 \(5\)。檢驗效能 \(\text{Power}=1-\beta\) 爲:\(Prob(X=5|H_1 \text{ is true})=(\frac{2}{3})^5=0.1317\)。顯著性水平 \(\alpha\) 爲 \(Prob(X=5|H_0 \text{ is true})=(\frac{1}{2})^5=0.03125\)。
- B 方法:當觀察到3,4,5次“成功”時,拒絕 \(H_0 (\text{i.e.} X=3,4,5)\)。此時判別區域 \(\mathfrak{R}\) 爲 \(3,4,5\)。檢驗效能 \(Power\) 爲:\(Prob(X=3,4,\text{ or }5|H_1 \text{ is ture})=\sum_{i=3}^5(\frac{2}{3})^i(\frac{1}{3})^{5-i}\approx0.7901\);顯著性水平 \(\alpha\) 爲:\(Prob(X=3,4,5|H_0 \text{ is true})=\sum_{i=3}^5(\frac{1}{2})^i(\frac{1}{2})^{5-i}=0.5\)
## [1] 0.7901## [1] 0.5比較上面兩種檢驗方法,可以看到,用B方法時,我們有更高的概率獲得假陽性結果(犯第一類錯誤,錯誤地拒絕 \(H_0\),接受 \(H_1\)),但是也有更高的檢驗效能 \(1-\beta\)(真陽性更高) 。這個例子就說明了,試圖提高檢驗效能的同時,會提高犯第一類錯誤的概率。實際操作中我們常常將第一類錯誤的概率固定,例如 \(\alpha=0.05\),然後儘可能選擇檢驗效能最高的檢驗方法。
15.3 如何選擇要檢驗的統計量
在上面的二項分佈的實驗中,“成功的次數” 是我們感興趣的要檢驗的統計量。但也可能是第一次出現 “成功” 之前的實驗次數,或者,任何與假設相關的統計量。相似的,如果觀察不是離散變量而是連續的,可以拿來檢驗的指標就有很多,如均值,中位數,衆數,幾何平均值等。
幸運地是,當明確了零假設和替代假設後,我們可以利用 Neyman-Pearson lemma 似然比公式1:
來決定使用哪個統計量做檢驗最有效:
\[\text{Neyman-Pearson lemma}=\frac{L_{H_0}}{L_{H_1}}\]
這公式很直觀,因爲當觀察數據更加支持 \(H_1\) 時 (\(L_{H_1}\) 更大),\(H_0\) 的可能性相對更小,就更應該被拒絕。而且,由於似然比越小,他的對數就越小,實際計算時我們常使用對數似然比:\(\ell_{H_0}-\ell_{H_1}\)。
問題來了,那到底要多小才算小?這個進入拒絕域的閾值由兩個指標來決定:
- 被檢驗統計量的樣本分佈 (the sampling distribution of the test statistic)
- 第一類錯誤概率 \(\alpha\) (the required value of \(\alpha\))
15.3.1 以已知方差的正態分佈爲例
假如已知 \(X_1, \cdots, X_n \stackrel{i.i.d}{\sim} N(\mu, \sigma^2)\) 而且方差 \(\sigma^2\) 也是已知的。如果令 \(H_0: \mu=5\; ;H_1: \mu=10\) 可以通過如下的方法找到我們需要的最佳檢驗統計量 best statistic 根據之前的推導 (Section 13) 可知正態分佈的似然方程如下:
\[\ell(\mu|\underline{x}) =-\frac{1}{2\sigma^2}\sum_{i=1}^n(x_i-\mu)^2\]
所以已知 \(\sigma^2\) 時,我們的零假設和替代假設之間的對數似然比 \(\ell_{H_0}-\ell_{H_1}\) 爲:
\[\ell_{H_0}-\ell_{H_1}=-\frac{1}{2\sigma^2}(\sum_{i=1}^n(x_i-5)^2-\sum_{i=1}^n(x_i-10)^2)\]
然而,我們只需要考慮隨着數據變化的部分,所以忽略掉不變的部分2:
\[ \begin{aligned} \ell_{H_0}-\ell_{H_1} & = -(\sum_{i=1}^n(x_i-5)^2-\sum_{i=i}^n(x_i-10)^2)\\ & = 75n - 2\times(10-5)\sum_{i=1}^nx_i \\ \end{aligned} \]
所以只要樣本和 (sum of sample) \(\sum_{i=1}^nx_i\) (最佳統計量 best statistic) 足夠大,零假設就會被拒絕。而且注意到最佳統計量可以乘以任何常數用作新的最佳統計量。爲了方便我們就用樣本均數 \(\frac{1}{n}\sum_{i=1}^nx_i\) 作此處的最佳統計量。所以此時,我們的最佳檢驗就是當樣本均值足夠大,超過某個閾值時,我們拒絕零假設。而且,樣本均值的樣本分佈是可以知道的,這樣就便於我們繼續計算下一步:拒絕域 (判別區域) 。
15.4 複合假設 composite hypotheses
目前爲止我們討論的假設檢驗限制太多,實際操作時,我們多考慮類似如下的假設:
- \(H_0: \theta=\theta_0 \;\text{v.s.}\; H_1: \theta>\theta_0\) [單側的替代假設]
- \(H_0: \theta=\theta_0 \;\text{v.s.}\; H_1: \theta\neq\theta_0\) [雙側的替代假設]
所以我們面臨的問題是簡單假設中用於判定的最佳統計量,是始終如一地適用?我們一一來看:
15.5 爲反對零假設 \(H_0\) 的證據定量
重新再考慮複合假設:\(H_0: \theta=\theta_0\;\text{v.s.}\;H_1: \theta>\theta_0\) 假如存在一個總是可用的最佳檢驗統計量,用 \(T\) 來標記 (或 \(T(x)\)), 這個統計量足夠大時,我們拒絕 \(H_0\)。 別忘了我們還要給事先固定好的顯著性水平 \(\alpha\) 定義與之相關的判別區域:
\[\text{Prob}(\underline{x}\in\mathfrak{R}|H_0)=\alpha\]
如果我們知道 \(T\) 的樣本分佈,我們就可以使用一個閾值 \(c\) 來定義這個判別區域:
\[Prob(T\geqslant c|H_0)=\alpha\]
更加正式的,我們定義判別區域 \(\mathfrak{R}\) 爲:
\[\{\underline{x}:\text{Prob}(T(x)\geqslant c|H_0)=\alpha\}\]
換句話說,當統計量 \(T>c\) 時,我們拒絕 \(H_0\) 。如果先不考慮拒絕或不拒絕的二元判定,我們可以用一個連續型測量值來量化反對零假設 \(H_0\) 的證據。再考慮從觀察數據中獲得的 \(T\) ,即數據告訴我們的 \(t\) 。所以,當 \(t\) 值越大,說明觀察值相對零假設 \(H_0\) 越往極端的方向走。因此我們可以用 \(T\) 的樣本分佈來計算觀察值大大於等於這個閾值(極端值) 時的概率:
\[p=\text{Prob}(T\geqslant t|H_0)\]
這個概率公式被稱爲是單側 \(p\) 值 (one-side p-value)。單側 \(p\) 值越小,統計量 \(T\) 的樣本空間就有越小比例(越強) 的證據支持零假設 \(H_0\)。
我們把這以思想用到假設檢驗中時,就可以認爲:
\[p<\alpha \Leftrightarrow t>c\]
所以用我們一貫的設定 \(\alpha=0.05\),所以如果計算獲得 \(p<0.05\) 我們就認爲獲得了足夠強的拒絕零假設 \(H_0\) 的證據。
15.5.1 回到正態分佈的均值比較問題上來(單側替代假設)
繼續考慮 \(X_1,\cdots,X_n\stackrel{i.i.d}{\sim} N(\mu, \sigma^2)\),假設 \(\sigma^2=10\),我們要檢驗的是 \(H_0: \mu=5 \;\text{v.s}.\; H_1: \mu>5\)
- 確定最佳檢驗統計量:已經證明過,單側替代假設的最佳檢驗統計量是樣本均值 \(\bar{x}\)。
- 確定該統計量的樣本分佈:已知樣本均數的樣本分佈是 \(\bar{X}\sim N(\mu,\sigma^2/n)\) 。
\(\Rightarrow Z=\frac{\bar{X}-\mu}{\sigma/\sqrt{n}} \sim N(0,1)\),所以在 \(H_0\) 條件下,\(\Rightarrow Z=\frac{\bar{X}-5}{\sqrt{10}/\sqrt{n}} \sim N(0,1)\) - 所以當一個檢驗的顯著性水平設定爲 \(\alpha=0.05\) 時,我們用判別區域 \(\mathfrak{R}\),使統計量據落在該判別區域內的概率爲 \(0.05\):
\(\text{Prob}(\bar{X}\geqslant c|H_0) = 0.05\)
已知在標準正態分佈時,\(\text{Prob}(Z\geqslant1.64)=0.05=\text{Prob}(\frac{\bar{X}-5}{\sqrt{10}/\sqrt{n}}\geqslant1.64)\) - 假設樣本量是 \(10\),那麼數據的判別區域 \(\mathfrak{R}\) 就是 \(\bar{X}\geqslant6.64\)。
- 假設觀察數據告訴我們,\(\bar{X}=7.76\) 。那麼這一組觀察數據計算得到的統計量落在了判別區域內,就提供了足夠的證據拒絕接受 \(H_0\)。
- 我們可以給這個觀察數據計算相應的單側 \(p\) 值:
\(p=\text{Prob}(\bar{X}\geqslant7.76|H_0)=\text{Prob}(Z+5\geqslant7.76)\\=\text{Prob}(Z\geqslant2.76)=0.003\)
所以,觀察數據告訴我們,在 \(H_0\) 的前提下,觀察值出現的概率是 \(0.3\%\) 。即,在無數次重複取樣實驗中,僅有 \(0.3\%\) 的結果可以給出支持 \(H_0\) 的證據。因此我們拒絕 \(H_0\) 接受 \(H_1\)。
15.6 雙側替代假設情況下,雙側 \(p\) 值的定量方法
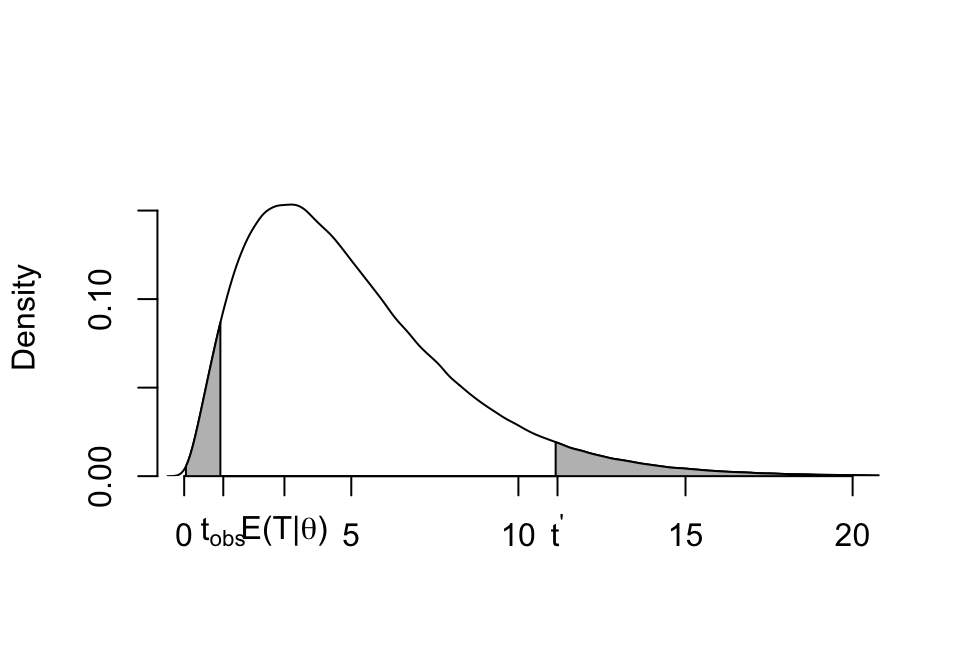
圖 15.1: Deliberately use an assymmetrical distribution to highlight the issues
此處故意使用一個左右不對稱的概率密度分佈來解釋。
現在的替代假設是雙側的:
\[H_0: \theta=\theta_0 \;\text{v.s.}\; H_1: \theta\neq\theta_0\]
正常來說,雙側的假設檢驗應該分成兩個單側檢驗。即:
- \(H_1: \theta>\theta_0\);
- \(H_1: \theta<\theta_0\).
每個單側檢驗都有自己的最佳檢驗統計量。令 \(T\) 是 1. 的最佳檢驗統計量,該統計量的樣本分佈如上圖 15.1 所示(左右不對稱) 。假如觀察數據給出的統計量爲 \(t_{\text{obs}}\),那麼在概率上反對零假設的情況可以有兩種:
- \(T\geqslant t_{\text{obs}}\) 其中, \(\text{Prob}(T\geqslant t_{\text{obs}}|H_0)=\tilde p\);
- \(T\leqslant t^\prime\) 其中,\(t^\prime\) 滿足: \(\text{Prob}(T\leqslant t^\prime|H_0) =\tilde p\)。(圖15.1)
所以概率密度分佈兩側的距離可以不對稱,但是只要左右兩側概率密度分佈的面積(\(=\tilde p\))相同,那麼就可以直接認爲,雙側 \(p\) 值是兩側面積之和 (\(p=2\times \tilde p\)),且觀察數據提供的統計量落在這兩個面積內的話,都足以提供證據拒絕零假設 \(H_0\)。
注意:
- 被選中的 \(t^\prime\) 值大小不大可能滿足:\(|t^\prime - E(T|\theta_0)|=|t_{obs}-E(T|\theta_0)|\)。因爲那只有在完全左右對稱的分佈中才會出現。但是,此處我們關心的是面積左右兩邊的尾部要相等即可,所以我們只需要知道右半邊,較大的那個 \(t_{obs}\) 就完全足夠了。
回到上面的均值比較問題 (Section 15.5.1)。現在我們要進行雙側假設檢驗,即: \(H_0: \mu=5 \text{ v.s. } H_1: \mu\neq5\),最佳統計量依然還是樣本均數 \(\bar{X}\)。數據告訴我們說 \(\bar{X}=7.76\),因此雙側 \(p\) 值就是將已求得的單側 \(\tilde p\) 值乘以 \(2\): \(\text{two-sided } p=2\tilde p= 0.006\)
當然,實際操作中我們很少進行這樣繁瑣的論證,多數情況下就直接報告雙側 \(p\) 值。
15.7 假設檢驗構建之總結
按照如下的步驟一一構建我們的假設檢驗過程:
- 先建立零假設,和替代假設 (Section 15.1);
- 定義最佳檢驗統計量 (用 Neyman-Pearson lemma) (Section 15.3);
- 取得零假設條件下,最佳統計量的樣本分佈(通常都較爲困難,有時候我們會傾向於使用“不太理想”,但是計算較爲簡便的過程。) ;
- 定義拒絕域(判別區域) (常用 \(\alpha=0.05\)) ;
- 計算觀察數據的檢驗統計量;
- 如果觀察數據的檢驗統計量落在了提前定義好的拒絕域內,那麼我們的檢驗結論就是:觀察數據拒絕了零假設支持替代假設。然而在實際操作時,如果發現數據的檢驗統計量不在拒絕域內,我們僅僅只能下結論說:觀察數據無法拒絕零假設(而不是接受零假設!) ;
- 報告計算得到的反對零假設的定量 \(p\) 值。
作爲統計學家,我們的任務是評價數據提供的證據,而不是簡單的去接受或者拒絕一個假設。
15.8 Inference Practical 07
15.8.1 Q1
某種藥物有兩種使用方法:可以口服,也可以注射。兩種方法都被認爲可以使血漿中藥物濃度在24小時候達到相似的平均水平,\(3 \mu \text{g/L}\)。已知口服該藥物後,濃度的方差爲 \(1\),而如果是注射的話方差只有 \(1/4\)。因此設計了一個口服臨牀實驗,觀察到24小時後血漿中藥物濃度數據爲:2.54, 0.93, 2.75, 4.51, 3.71, 1.62, 3.01, 4.13, 2.08, 3.33。假設這組觀察數據獨立同分佈 \(\stackrel{i.i.d}{\sim} N(3, \sigma^2)\)
- 證明以下的假設的最佳檢驗統計量是 \(\sum_{i=1}^{10}(x_i-3)^2\): \[H_0: \sigma^2=1/4 \text{ v.s. } H_1: \sigma^2=1\]
解
根據 Neyman-Pearson lemma (Section 15.3) 來判斷最佳檢驗統計量:
下面用 \(\sigma^2_0, \sigma^2_1\) 分別標記零假設和替代假設時的方差。
\[ \begin{aligned} L(\sigma^2|\underline{x},\mu=3) &= \prod_{i=1}^n\frac{1}{\sqrt{2\pi\sigma^2}}\text{exp}(-\frac{1}{2}(\frac{x_i-3}{\sigma})^2) \\ \Rightarrow \ell(\sigma^2) &=-\frac{1}{2}\sum_{i=1}^n\text{log}\sigma^2-\frac{1}{2\sigma^2}\sum_{i=1}^n(x_i-3)^2 \\ &= -\frac{n}{2}\text{log}\sigma^2-\frac{1}{2\sigma^2}\sum_{i=1}^n(x_i-3)^2 \\ \Rightarrow \ell(\sigma_0^2)-\ell(\sigma_1^2)&= \frac{n}{2}\text{log}\sigma_1^2+\frac{1}{2\sigma_1^2}\sum_{i=1}^n(x_i-3)^2\\ &\;\;\;\;\;\;-\frac{n}{2}\text{log}\sigma_0^2-\frac{1}{2\sigma_0^2}\sum_{i=1}^n(x_i-3)^2\\ &=\frac{n}{2}(\text{log}\sigma_1^2-\text{log}\sigma_0^2)+\frac{1}{2}(\frac{1}{\sigma_1^2}-\frac{1}{\sigma_0^2})\sum_{i=1}^n(x_i-3)^2\\ &=\frac{n}{2}\text{log}\frac{\sigma_1^2}{\sigma_0^2}+\frac{1}{2}(\frac{1}{\sigma_1^2}-\frac{1}{\sigma_0^2})\sum_{i=1}^n(x_i-3)^2 \end{aligned} \]
觀察上面的式子就會發現,當實驗重複後唯一會發生變化的就是後面的 \(\sum_{i=1}^n(x_i-3)^2\)。 由於,\(\sigma_0^2=1/4, \; \sigma_1^2=1\),所以 \((\frac{1}{\sigma_1^2}-\frac{1}{\sigma_0^2})<0\)。那麼當 \(\sum_{i=1}^n(x_i-3)^2\) 越大,\(\ell(\sigma_0^2)-\ell(\sigma_1^2)\) 就越小。因此,這就是我們尋找的最佳檢驗統計量。
- 證明上面的檢驗統計量總是可以作爲最佳檢驗統計量,用於檢驗單側替代假設:\(H_1: \sigma^2>1/4\)。
上面的替代假設中 \(\sigma_1^2=1\),如果將替代假設改成 \(\sigma_1^2>1/4\),那麼 \((\frac{1}{\sigma_1^2}-\frac{1}{\sigma_0^2})<0\) 依然成立。所以,\(\sum_{i=1}^n(x_i-3)^2\),或者這部分乘以任何一個不變的常數依然是替代假設爲 \(H_1: \sigma^2>1/4\) 時的最佳檢驗統計量。
- 在 \(H_0\) 條件下,樣本分佈 \(\sum_{i=1}^{10}(x_i-3)^2\) 是怎樣的分佈?利用這個分佈來定義顯著性水平爲 \(\alpha=0.05\) 時的拒絕域。
在\(H_0\) 條件下,有: \[X_1,\cdots,X_n\stackrel{i.i.d}{\sim}N(3,1/4)\\ \Rightarrow \frac{X_i-3}{\sqrt{1/4}}\sim N(0,1)\\ \Rightarrow (\frac{X_i-3}{\sqrt{1/4}})^2 \sim \mathcal{X}_1^2\\ \Rightarrow \sum_{i=1}^{10}(\frac{X_i-3}{\sqrt{1/4}})^2 \sim \mathcal{X}_{10}^2\\ \Rightarrow 4\sum_{i=1}^{10}(X_i-3)^2\sim \mathcal{X}_{10}^2\\ \text{Let } T=\sum_{i=1}^{10}(X_i-3)^2\\ \Rightarrow 4T \sim \mathcal{X}_{10}^2\]
拒絕域被定義爲檢驗統計量取大於等於某個臨界值時概率爲 \(0.05\),即 \(\text{Prob}(T\geqslant t)=0.05\)
\[\text{Prob}(4T\geqslant \mathcal{X}^2_{10,0.95})=0.05\\ \Rightarrow \text{Prob}(T\geqslant 1/4\mathcal{X}^2_{10,0.95})=0.05\]
所以,此處當顯著性水平定爲 \(\alpha=0.05\) 時,拒絕域就是要大於自由度爲 \(10\) 的卡方分佈的 \(95\%\) 分位點。
- 在 \(H_0\) 條件下,該檢驗統計量的正態分佈模擬是怎樣的?
根據中心極限定理(Section 8) 和 卡方分佈的性質 (Section 11)
\[n\rightarrow \infty, X_n^2\sim N(n, 2n)\]
所以近似地,
\[\mathcal{X}_{10}^2\sim N(\text{E}(\mathcal{X}_{10}^2)=10,\text{Var}(\mathcal{X}_{10}^2)=20)\\ \Rightarrow 4T\sim \text{approx} N(10,20)\\ \Rightarrow \frac{4T-10}{\sqrt{20}} \stackrel{\cdot}{\sim} N(0,1)\]
- 用上面的正態分佈模擬,和觀察嘗試對單側替代假設作統計檢驗並依據所得結果作出結論:\[H_0: \sigma^2=1/4 \text{ v.s. } H_1: \sigma^2>1/4\]
用上面的正態分佈近似法,我們可以計算拒絕域:
\[\text{Prob}(\frac{4T-10}{\sqrt{20}}\geqslant Z_{0.95})=0.05\]
已知標準正態分佈的 \(95\%\) 分位點取值 \(1.64\),所以拒絕域:
\[\frac{4T-10}{\sqrt{20}}\geqslant 1.64\\ \Rightarrow T\geqslant1/4(10+1.64\sqrt{20})=1/4\times17.33\]
由觀察數據可得:\(T=11.5\) ,所以觀察數據的檢驗統計量落在了拒絕域內。我們的結論是:觀察數據提供了極強的證據證明在顯著性水平爲 \(5\%\) 時,口服該藥物24小時後的血漿藥物濃度的方差大於 \(1/4\)。
區分與之前討論的對數似然比 (Section 13),之前討論的對數似然比指的是所有的似然和極大似然之間的比,此處的似然比只是純粹在探討兩個假設之間的似然比,與極大似然無關。↩︎
Rememer that \(\ell_{H_0}-\ell_{H_1}\) is a random variable: the data varies each time we sample, with consequently varying relative support for the hypotheses, and so we are only interested in that part of \(\ell_{H_0}-\ell_{H_1}\) which depends on the results, the data, which vary with each sample (i.e. which contains the random part); the constant part provides no information on the relative support the data give to the hypotheses, so we ignore it.↩︎