第 64 章 流行病學中的邏輯迴歸
64.1 流行病學研究最常用的實驗設計
在流行病學研究中,我們最關心的無非是 暴露變量 (治療方案的選用,或者一些對象的某些特徵如吸菸或飲酒等生活習慣) 與結果變量 (罹患某種我們關心的疾病與否,或者死亡與否) 之間的關係。爲了方便解釋本章暫且只考慮 單一的結果變量 (univariate) 的情況,不過不要忘了真實世界中的數據和實驗,我們常要 同時處理多個不同的結果變量 (multivariate)。
流行病學最常用的兩種研究設計是:
- 隊列研究/前瞻性研究 cohort or prospective studies;
- 病例對照/回顧性研究 case-control or retrospective studies。
無論是這兩種研究中的哪一種,都要從定義研究的人羣開始 (start by defining some population we wish to study)。例如某個年齡段的男性或者女性;某個特定時間段內,在某特定地區範圍內生活的所有人等。這被定義爲 潛在研究人羣 (underlying population of interest)。
如果是隊列研究,我們需要對這個潛在研究人羣取樣,選取具 有代表性的,且有足夠樣本量 的一羣個體 (隊列) 參與研究。那些我們要研究的 暴露變量 \((\mathbf{X})\) 被提前定義好,然後在開始研究的時候收集整理成數據庫。之後這個隊列的參與者不斷被隨訪,這個時間段可以是先定義好的 (一年,五年,十年…),也可以因人而異,最終直至每個個體的結果變量被觀測到 \((D=1 \text{ or } D=0)\)。更一般地,如果我們要研究的暴露因素是二進制的,甚至是多分類的,我們可能會使用一些取樣的技巧,從而保證取樣構成的隊列能夠真實地反應該暴露因子在人羣中的分佈情況,保證隊列的代表性。
如果是病例對照研究,從它的別名 – 回顧性研究 – 也可以看出,它的研究起點和隊列研究相反,是從收集到的病例開始的 \((D=1)\)。有了病例以後,我們從人羣中沒有該結果變量 \((D=0)\) 的人羣中,取適合樣本量的人作爲對照組。然後再分別對病例和對照組用採訪或者問卷,或者調取過去的病例記錄/數據庫記錄等等尋找他們是否接觸過我們要研究的暴露變量。
到這裏,如果你還沒暈,恭喜你應該能理解爲什麼說病例對照研究研究的是 “結果的原因/causes of effect”;隊列研究研究的是 “原因導致的結果/effect of causes”。二者的終極目標卻是一致的 – 尋找暴露和結果二者之間的關係/To investigate the association between exposures and the outcomes – 只是手段不同而已。
觀察性研究 (不論是隊列還是病例對照研究),除了我們一定會測量並收集的暴露變量數據,在分析過程中還不可避免地需要把混雜效應考慮進來,也就是我們還必須測量並收集那些潛在的混雜因子的數據 \((W)\)。圖 64.1 用簡單示意圖總結了 \(W (\text{ confounders }), X (\text{ exposures }), D (\text{ outcomes })\) 之間,在不同實驗設計下的關係。
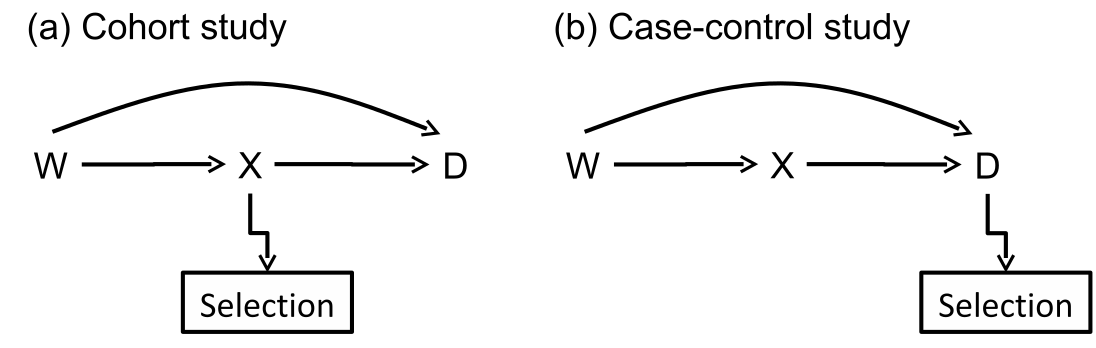
圖 64.1: Path diagrams showing relationships between variables in the underlying population and selection to a cohort study and a case-control study.
64.2 以簡單二進制暴露變量爲例
64.2.1 先決條件
我們以一個最簡單的二進制暴露變量 \((X)\) (例如是否接觸了某種化學試劑),和一個二進制結果變量 \((D)\) (是否患有食道癌) 爲例展開:
- 觀察對象樣本量爲 \(n, i = 1,\cdots,n\);
- \(X_i\) 爲一個二進制暴露變量 (是否接觸了某種化學試劑,\(1=\)是,\(0=\)否);
- \(D_i\) 爲一個二進制結果變量 (是否有食道癌,\(1=\)是,\(0=\)否)。
所以,該研究的潛在研究人羣可以被分成四組:\((X=1,D=1),(X=1,D=0),(X=0,D=1),(X=0,D=0)\)。如果用 \(\pi_{11}, \pi_{10}, \pi_{01}, \pi_{00}\) 標記每組人在該潛在研究人羣中所佔的比例,那麼有:
\[ \begin{aligned} \pi_{xd} & = \text{Pr}(X=x, D=d) \\ \pi_{11} &+ \pi_{10} + \pi_{01} + \pi_{00} = 1 \end{aligned} \tag{64.1} \]
| \(0\) | \(1\) | ||
|---|---|---|---|
| \(X\) | \(0\) | \(\pi_{00}\) | \(\pi_{01}\) |
| \(1\) | \(\pi_{10}\) | \(\pi_{11}\) |
這裏我們應用概率標記法來輔助理解隊列研究:我們從潛在研究人羣中抽樣,觀察其暴露情況,再追蹤其結果變量。所以實際上,隊列研究的樣本,來自與對暴露與否 \((X=0, X=1)\) 兩組人的抽樣,所以我們實際求的是,
\[ \begin{equation} \text{Pr}(D=d|X=x) = \frac{\pi_{xd}}{\pi_{x0} + \pi_{x1}} \end{equation} \]
| \(D\) | \(\text{Pr}(D=d|X=x)\) | ||
|---|---|---|---|
| \(X\) | \(0\) | \(1\) | |
| \(0\) | \(\pi_{00}\) | \(\pi_{01}\) | \(\frac{\pi_{01}}{\pi_{01} + \pi_{00}}\) |
| \(1\) | \(\pi_{10}\) | \(\pi_{11}\) | \(\frac{\pi_{11}}{\pi_{10} + \pi_{11}}\) |
相反地,病例對照研究中我們從已有的病例 \((D=1)\) 出發,這樣做的理由有很多,通常可能由於病例可能十分稀少,如果建立隊列研究可能需要龐大的樣本量 (即便如此也不一定能夠收集到足夠分析的數據,可能還要花費相當長的隨訪時間,吃力不討好)。所以,在病例對照研究的設計中,我們其實是獨立地從兩個人羣 (病例組,\(D=1\),對照組,\(D=0\)) 中抽取樣本。所以,病例對照研究獲得的數據,只能用於計算暴露在病例組和對照組中的條件概率:
\[ \text{Pr}(X=x|D=d) = \frac{\pi_{xd}}{\pi_{0d}+\pi_{1d}} \]
| \(0\) | \(1\) | ||
|---|---|---|---|
| \(X\) | \(0\) | \(\pi_{00}\) | \(\pi_{01}\) |
| \(1\) | \(\pi_{10}\) | \(\pi_{11}\) | |
| \(\text{Pr}(X=x|D=d)\) | \(\frac{\pi_{10}}{\pi_{10}+\pi_{00}}\) | \(\frac{\pi_{11}}{\pi_{11}+\pi_{01}}\) |
64.2.2 比值比 Odds ratios
某研究的數據中,暴露變量是二進制的 \(X\),和 結果變量是二進制的 \(D\)。我們其實最關心的問題是:結果變量的兩個分類 \(D=0, D=1\),在暴露變量 \(X=0, X=1\) 兩組中到底個佔多少比例。用吸菸與肺癌的例子來解釋就是,我們最關心的是,在吸菸人羣中,發生肺癌的人的比例,是否顯著地高於非吸菸人羣中發生肺癌的人的比例,僅此而已。這句話用概率論的標記法來寫的話,則是兩個條件概率:\(\text{Pr}(D=1|X=1), \text{Pr}(D=1|X=0)\)。此處,可以定義暴露變量 \(X=1\) 的條件下,結果變量 \(D=1\) 的概率的比值 (Odds):
\[ \text{Odds}_1 = \frac{\text{Pr}(D=1|X=1)}{1-\text{Pr}(D=1|X=1)} = \frac{\pi_{11}/(\pi_{10} + \pi_{11})}{1-\pi_{11}/(\pi_{10} + \pi_{11})} \]
類似地,暴露變量 \(X=0\) 的條件下,結果變量 \(D=1\) 的概率的比值 (Odds):
\[ \text{Odds}_2 = \frac{\text{Pr}(D=1|X=0)}{1-\text{Pr}(D=1|X=0)} = \frac{\pi_{01}/(\pi_{01} + \pi_{00})}{1-\pi_{01}/(\pi_{01} + \pi_{00})} \]
故,從隊列研究中,可以很自然的計算暴露變量和結果變量的比值比:
\[ \begin{aligned} \text{Odds Ratio}_{\text{cohort}} = \frac{\text{Odds}_1}{\text{Odds}_2} & = \frac{\frac{\text{Pr}(D=1|X=1)}{1-\text{Pr}(D=1|X=1)}}{\frac{\text{Pr}(D=1|X=0)}{1-\text{Pr}(D=1|X=0)}}\\ & = \frac{\frac{\pi_{11}/(\pi_{10} + \pi_{11})}{1-\pi_{11}/(\pi_{10} + \pi_{11})}}{\frac{\pi_{01}/(\pi_{01} + \pi_{00})}{1-\pi_{01}/(\pi_{01} + \pi_{00})}} \\ & = \frac{\frac{\pi_{11}/(\pi_{10}+\pi_{11})}{\pi_{10}/(\pi_{10}+\pi_{11})}}{\frac{\pi_{01}/(\pi_{01}+\pi_{00})}{\pi_{00}/(\pi_{01}+\pi_{00})}} \\ & = \frac{\pi_{11}\pi_{00}}{\pi_{10}\pi_{01}} \end{aligned} \]
從病例對照研究中,推算的暴露變量和結果變量的比值比是另外一個過程:
\[ \begin{aligned} \text{Odds Ratio}_{\text{case-control}} = \frac{\text{Odds}^\prime_1}{\text{Odds}^\prime_2} & = \frac{\frac{\text{Pr}(X=1|D=1)}{1-\text{Pr}(X=1|D=1)}}{\frac{\text{Pr}(X=0|D=0)}{1-\text{Pr}(X=0|D=0)}} \\ & = \frac{\frac{\pi_{11}/(\pi_{11} + \pi_{01})}{1-\pi_{11}/(\pi_{11} + \pi_{01})}}{\frac{\pi_{10}/(\pi_{10} + \pi_{00})}{1-\pi_{10}/(\pi_{10} + \pi_{00})}} \\ & = \frac{\frac{\pi_{11}/(\pi_{11}+\pi_{01})}{\pi_{01}/(\pi_{11}+\pi_{01})}}{\frac{\pi_{10}/(\pi_{10}+\pi_{00})}{\pi_{00}/(\pi_{10}+\pi_{00})}} \\ & = \frac{\pi_{11}\pi_{00}}{\pi_{10}\pi_{01}} \end{aligned} \]
經過上面的推演,我們發現用病例對照研究的數據,雖然不能像隊列研究一樣直接推算正確的暴露條件下的比值 (conditional odds given exposure),卻能用較少的樣本量中獲得真實的比值比 (OR) 。
64.2.3 邏輯迴歸應用於病例對照研究的合理性
在一個隊列研究中,當我們有不止一個暴露變量時,顯然就需要更加複雜的模型來輔助分析 (迴歸型分析法) 暴露變量和結果變量之間的關係。估計比值比最佳的模型是邏輯迴歸。如果 \(D\) 表示一個隨機型結果變量,其中每個觀察對象的結果變量服從暴露變量的條件二項分佈 (繼續用單一的二進制暴露變量 \(x_i\)):
\[ D_i|X_i = x_i \sim \text{Binomial}(1, \pi_i) \]
所以,可以用邏輯迴歸來擬合:
\[ \text{logit}(\pi_i) = \text{log}(\frac{\pi_i}{1-\pi_i}) = \alpha + \beta x_i \]
把這個邏輯迴歸方程重新整理:
\[ \begin{aligned} \text{Pr}(D=1|X=1) & = \frac{e^{\alpha + \beta}}{1 + e^{\alpha + \beta}} \\ \text{Pr}(D=1|X=0) & = \frac{e^\alpha}{1 + e^\alpha} \\ \text{Where, }\alpha & = \text{log}{\frac{\pi_{01}}{\pi_{00}}} \\ \beta & = \text{log}{\frac{\pi_{11}\pi_{00}}{\pi_{10}\pi_{01}}} \end{aligned} \]
在一個病例對照研究中,結果變量 \(D_i\) 被鎖死,暴露變量成了服從結果變量的條件二項分佈的隨機變量:
\[ X_i | D_i = d_i \sim \text{Binomial}(1,\pi_i^*) \]
繼續任性地用邏輯迴歸擬合的話:
\[ \text{logit}(\pi_i^*) = \text{log}(\frac{\pi_i^*}{1-\pi_i^*}) = \alpha^* + \beta d_i \]
同樣整理成概率方程:
\[ \begin{aligned} \text{Pr}(X=1|D=1) & = \frac{e^{\alpha^* + \beta}}{1 + e^{\alpha^* + \beta}} \\ \text{Pr}(X=1|D=0) & = \frac{e^{\alpha^*}}{1 + e^{\alpha^*}} \\ \text{Where, }\alpha & = \text{log}{\frac{\pi_{10}}{\pi_{00}}} \\ \beta & = \text{log}{\frac{\pi_{11}\pi_{00}}{\pi_{10}\pi_{01}}} \end{aligned} \]
所以,用邏輯迴歸擬合病例對照研究的數據,同樣可以得到和隊列研究一樣正確的比值比估計。但是這個截距 \(\alpha\),在隊列研究中指的是,非暴露組中患病的比值的對數 (log odds of disease in the unexposed);在病例對照研究中指的是,對照組中暴露的比值的對數 (log odds of exposure in the controls)。是兩個完全不同含義的估計量。
綜上所述,從一個隊列研究獲得的似然方程是:
\[ \begin{aligned} L_{\text{cohort}} & = \prod_{i=1}^n(\frac{e^{\alpha + \beta x_i}}{1+e^{\alpha + \beta x_i}})^{d_i}(\frac{1}{e^{\alpha + \beta x_i}})^{1-d_i} \\ \text{Where } d_i & = \left\{ \begin{array}{ll} 0 \text{ if subjects were not observed with the outcome}\\ 1 \text{ if subjects were observed with the outcome}\\ \end{array} \right. \\ x_i & = \left\{ \begin{array}{ll} 0 \text{ if subjects were not observed with the exposure}\\ 1 \text{ if subjects were observed with the exposure}\\ \end{array} \right. \end{aligned} \]
從一個病例對照研究獲得的似然方程是:
\[ \begin{aligned} L_{\text{case-control}} & = \prod_{i=1}^n(\frac{e^{\alpha + \beta d_i}}{1+e^{\alpha + \beta d_i}})^{x_i}(\frac{1}{e^{\alpha + \beta d_i}})^{1-x_i} \\ \text{Where } d_i & = \left\{ \begin{array}{ll} 0 \text{ if subjects were not observed with the outcome}\\ 1 \text{ if subjects were observed with the outcome}\\ \end{array} \right. \\ x_i & = \left\{ \begin{array}{ll} 0 \text{ if subjects were not observed with the exposure}\\ 1 \text{ if subjects were observed with the exposure}\\ \end{array} \right. \end{aligned} \]
64.3 拓展到多個暴露變量的邏輯迴歸模型
現在來考慮 \(p\) 個暴露變量的情況:\(X_1, \cdots, X_p\),這些暴露變量可以是分類型變量,也可以是連續型變量,例如,
- \(D_i = 0 \text{ or } 1\),第 \(i\) 名研究對象觀察到有 \((=1)\),或沒有 \((=0)\) 結果變量 (如發生胰腺癌);
- \(X_{i1} = 0 \text{ or } 1\),第 \(i\) 名研究對象有 \((=1)\),或沒有 \((=0)\) 暴露變量 (如吸菸);
- \(X_{i2} = 0 \text{ or } 1\),第 \(i\) 名研究對象是男性 \((=1)\),或女性 \((=0)\);
- \(X_{i3}\),第 \(i\) 名研究對象的年齡 (years)。
64.3.1 Mantel Haenszel 法
如果數據有且只有兩個暴露變量,\(X_1, X_2\),其中 \(X_1\) 是一個二進制變量,\(X_2\) 是一個可以分成 \(C\) 組的分類變量。那麼如果樣本量足夠大,可以把數據整理成 \(C\) 個四格表用於分析每一個 \(X_2\) 的分層中 \(X_1\) 和結果變量 \(D\) 之間的關係。多層數據的合併比值比可以用 Mantel Haenszel 法。此法在兩個分類暴露變量的情況下還能適用,當某個(或兩個)分類變量的層數越來越多時,你會發現最終落到小格子裏的樣本量急劇下降,侷限性就體現了出來。另外,此法亦不能應用於連續型變量的調整,用處簡直就是捉襟見肘。迫切地我們需要有更加一般的 (藉助於迴歸的威力的) 方法來對多個暴露變量進行調整。
64.3.2 隊列研究和病例對照研究的似然
一個隊列研究,用邏輯迴歸擬合其結果變量 (因變量) \(D\) 和暴露變量 \(X_1, \cdots, X_p\) 之間的關係時,可以寫作:
\[ \begin{aligned} D_i=1 | (X_{i1} & = x_{i1}, \cdots, X_{ip} = x_{ip}) \sim \text{Binomial}(1, \pi_i) \\ \text{logit} (\pi_i) & = \text{log}(\frac{\pi_i}{1-\pi_i}) = \alpha + \beta_1 x_{i1} + \cdots + \beta_p x_{ip} \end{aligned} \]
將這個迴歸方程重新整理成爲概率方程:
\[ \text{Pr}(D_i = 1 | X_{i1} = x_{i1}, \cdots, X_{ip} = x_{ip}) = \frac{e^{\alpha + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}}}{1+e^{\alpha + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}}} \]
- 截距 \(\alpha\) 的含義是,當所有的暴露變量都取 \(0\) 時,研究對象觀察到結果變量爲 \(1\) 的對數比值 \((\text{log odds})\);
- 迴歸係數 \(\beta_k\) 的含義是,當其餘的暴露變量保持不變時,\(x_k\) 每增加一個單位,結果變量爲 \(1\) 的對數比值比 \((\text{log odds-ratio})\) (即,調整了其餘所有變量之後,\(x_k\) 和結果變量之間的對數比值比)。
所以,隊列研究的數據,其似然方程是:
\[ \begin{aligned} L_{\text{cohort}} & = \prod_{i=1}^n\text{Pr}(D_i = d_i | X_{i1} = x_{i1}, \cdots, X_{ip} = x_{ip}) \\ & = \prod_{i=1}^n\text{Pr}(\frac{e^{\alpha + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}}}{1+e^{\alpha + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}}})^{d_i}(\frac{1}{1+e^{\alpha + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}}})^{1-d_i} \end{aligned} \]
當數據變成了病例對照研究,其似然方程會變成怎樣呢?
\[ L_{\text{case-control}} = \prod_{i=1}^n\text{Pr}(X_{i1} = x_{i1}, \cdots, X_{ip} = x_{ip} |D_i = d_i) \]
這裏,我們很難看出這到底是怎樣的一個條件概率,如果預測變量中同時包括了連續型變量和分類變量,情況就更加複雜,剪不斷理還亂。
64.3.3 病例對照研究中的邏輯迴歸
用 \(\text{Pr}(S_i=1 \text{ or } 0)\) 表示在潛在研究人羣 (underlying study population) 中,被抽樣 (或者沒有被抽樣) 進入該隊列研究的概率。那麼,理想情況下,可認爲實施病例對照研究時,病例是稀少的,即我們收集到的病例,幾乎等價於我們關心的潛在研究人羣中全部的病例,且可以被證明:
\[ \begin{aligned} & \text{Pr}(X_{i1} = x_{i1}, \cdots, X_{ip} = x_{ip} |D_i = 1) \\ =& \text{Pr}(X_{i1} = x_{i1}, \cdots, X_{ip} = x_{ip} |D_i = 1, S_i=1) \\ =& \frac{e^{\alpha^* + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}}}{1+e^{\alpha^* + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}}} \\ & \;\;\;\; \times \frac{\text{Pr}(X_{i1} = x_{i1}, \cdots, X_{ip} = x_{ip} |S_i=1)}{\text{Pr}(D_i = 1 | S_i = 1)} \\ \text{Where } \alpha^* & = \alpha + \text{log}(\frac{\text{Pr}(D_i = 0)}{\text{Pr}(D_i = 1)}) + \text{log}(\frac{\text{Pr}(D_i = 1|S_i=1)}{\text{Pr}(D_i = 0|S_i=1)}) \end{aligned} \tag{64.2} \]
概率方程 (64.2) 中,可以看出第一部分 \(\frac{e^{\alpha^* + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}}}{1+e^{\alpha^* + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}}}\) 是一個邏輯迴歸模型。跟隊列研究的邏輯迴歸模型相比較,差別只是截距不同 \(\alpha \neq \alpha^*\)。其餘的部分如 \(\text{Pr}(X_{i1} = x_{i1}, \cdots, X_{ip} = x_{ip} |S_i=1)\) 的含義是潛在人羣中被取樣放入該隊列研究,且預測變量各自不同的隨機概率分佈,其實和我們尋找的參數 \(\beta_1,\cdots,\beta_p\),是沒有什麼關係的。最後一部分分母的 \(\text{Pr}(D_i = 1 | S_i = 1)\) 的意思是,結果變量爲 \(1\) 的人被選入本項病例對照研究的概率,理想的實驗設計下這被認爲是接近於 \(1\) 的,即使不是,它也是一個固定不變的常數。所以,病例對照研究的似然方程中,我們關心的只有第一部分,邏輯迴歸模型:
\[ L_{\text{case-control}} \propto \prod_{i=1}^n(\frac{e^{\alpha^* + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}}}{1+e^{\alpha^* + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}}})^{d_i}(\frac{1}{1+e^{\alpha^* + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}}})^{1-d_i} \]
這裏必須明確的一點是,病例對照研究擬合的邏輯迴歸,其截距是 \(\alpha^*\),並非 \(\alpha\)。這個 \(\alpha^*\) 其實是包含了 \(\text{Pr}(D_i=1),\text{Pr}(D_i=0)\) 的,可惜這些概率也無法用病例對照研究設計獲得。所以,病例對照研究數據擬合了邏輯迴歸模型以後的截距,其實沒有太多實際的含義。
64.4 流行病學研究中變量的調整策略
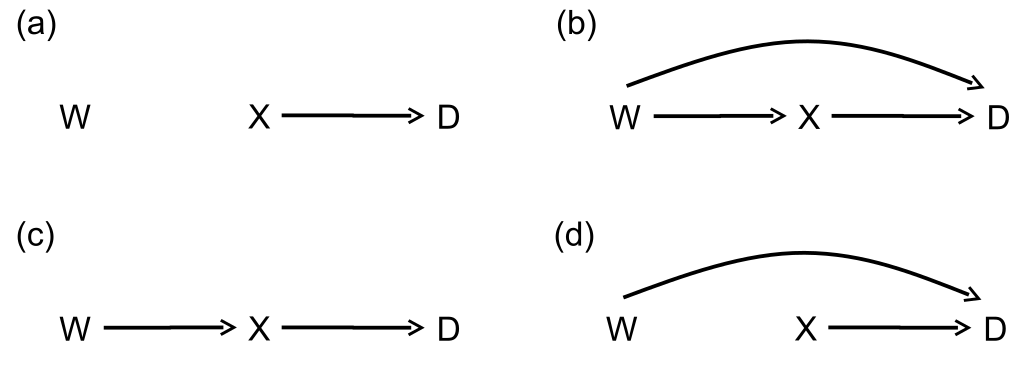
圖 64.2: relationships between three variables in an underlying population of interest
圖 64.2 展示的是在潛在研究人羣中 \(W (\text{potential confounder}),X (\text{exposure}),D (\text{outcome})\) 三者之間可能存在的四種關係。
- 圖 64.2 - (a) \(W\) 和 \(X, D\) 都沒有關係,那麼我們研究 \(X,D\) 之間的關係時,完全可以忽略掉 \(W\),不用調整。
但是,如果在邏輯迴歸模型中調整了一個和暴露變量結果變量之間無關的變量,獲得的比值比估計幾乎不會有太大改變,但是代價是會獲得較大的對數比值比的標準誤 (standard error),降低了對比值比估計的精確程度。 - 圖 64.2 - (b) \(W\) 和 \(X, D\) 同時都相關,且不在 \(X\rightarrow D\) 的因果關係通路上,此種情況下,必須對 \(W\) 進行調整,否則獲得的比值比估計是帶有嚴重偏倚的。
- 圖 64.2 - (c) \(W\) 僅僅和 \(X\) 有關係,和結果變量 \(D\) 沒有相關性。此時研究 \(X,D\) 之間的關係時,忽略掉 \(W\),不需要對之進行任何調整。和 (a) 一樣,如果此時調整了 \(W\),估計的比值比不會發生質變,但是會損失估計的精確度。
- 圖 64.2 - (d) \(W\) 僅僅和結果變量 \(D\) 有關係,和暴露變量 \(X\) 無關時,如果模型對 \(W\) 進行調整,我們會獲得完全不同的比值比估計,因爲這種情況下其實調整 \(W\) 前後的比值比估計的是具有不同含義的,二者都具有實際意義。調整前的估計量,是總體估計,有助於作總體的決策;調整後的估計量,是帶有某些特徵的部分人羣估計,有助於評價個人水平的 \(X,D\) 之間的關係。
64.5 GLM Practical 08
64.5.1 Part 1
在第一部分的數據分析中,我們會使用邏輯回歸模型來分析來自病例對照研究設計的數據,並獲取比值比 (odds ratios)。
該病例對照研究數據來自一項關於食道癌的研究 (Breslow, Day, and research 1980)。病例是200名被診斷爲患有食道癌的法國男性。對照組則來自176名健康男性。
數據包含的變量及其解釋描述如下:
| Variable Name | Content |
|---|---|
case |
1 = case, 0 = control |
age_group |
age group [1: 25-34; 2: 35-44; 3: 45-54; 4: 55-64; 5: 65-74; 6: 75+] |
tobacco_group |
tobacco intake group [0: None; 1: 1-9 g/d; 2: 10-19 g/d; 3: 20-29 g/day; 4: 30+ g/d] |
alcohol_grp |
alcohol intake group [0: 0-39 g/d; 1: 40-79 g/d; 80-119 g/d; 3: 120+ g/d] |
該研究的主要目的是分析吸菸量 tobacco_group 與飲酒量 alcohol_grp 是否是食道癌的危險因子。變量中的年齡 age_group 則作爲唯一已知的混雜因子。
64.5.1.1 簡單初步總結各個解釋變量的分佈及特徵。思考吸菸量和飲酒量,吸菸量和年齡之間有怎樣的關係。
Oesophageal <- read_dta("../backupfiles/oesophageal_data-1.dta")
tab <- stat.table(index=list(Tobacco_gr = tobacco_group,
Alcohol_gr = alcohol_grp),
contents=list(count(),
percent(alcohol_grp)),
data=Oesophageal, margins=TRUE)
print(tab, digits = 2)## -----------------------------------------------------
## ---------------Alcohol_gr----------------
## Tobacco_gr 0 1 2 3 Total
## -----------------------------------------------------
## 0 148.00 83.00 27.00 6.00 264.00
## 56.06 31.44 10.23 2.27 100.00
##
## 1 112.00 97.00 35.00 18.00 262.00
## 42.75 37.02 13.36 6.87 100.00
##
## 2 84.00 85.00 49.00 18.00 236.00
## 35.59 36.02 20.76 7.63 100.00
##
## 3 42.00 62.00 16.00 12.00 132.00
## 31.82 46.97 12.12 9.09 100.00
##
## 4 28.00 29.00 12.00 13.00 82.00
## 34.15 35.37 14.63 15.85 100.00
##
##
## Total 414.00 356.00 139.00 67.00 976.00
## 42.42 36.48 14.24 6.86 100.00
## -----------------------------------------------------tab <- stat.table(index=list(Tobacco_gr = tobacco_group,
Age_gr = age_group),
contents=list(count(),
percent(age_group)),
data=Oesophageal, margins=TRUE)
print(tab, digits = 2)## ---------------------------------------------------------------------
## -------------------------Age_gr--------------------------
## Tobacco_gr 1 2 3 4 5 6 Total
## ---------------------------------------------------------------------
## 0 50.00 69.00 56.00 50.00 26.00 13.00 264.00
## 18.94 26.14 21.21 18.94 9.85 4.92 100.00
##
## 1 21.00 40.00 48.00 67.00 73.00 13.00 262.00
## 8.02 15.27 18.32 25.57 27.86 4.96 100.00
##
## 2 19.00 46.00 57.00 65.00 38.00 11.00 236.00
## 8.05 19.49 24.15 27.54 16.10 4.66 100.00
##
## 3 11.00 27.00 33.00 38.00 20.00 3.00 132.00
## 8.33 20.45 25.00 28.79 15.15 2.27 100.00
##
## 4 16.00 17.00 19.00 22.00 4.00 4.00 82.00
## 19.51 20.73 23.17 26.83 4.88 4.88 100.00
##
##
## Total 117.00 199.00 213.00 242.00 161.00 44.00 976.00
## 11.99 20.39 21.82 24.80 16.50 4.51 100.00
## ---------------------------------------------------------------------似乎在吸菸量和飲酒量之間存在正關係,吸菸較多的人,飲酒量也呈現較多的趨勢。另外,不吸菸的人中,以及吸菸量最多的人中,都有較多的年輕人。吸菸量和飲酒量也許都和患有食道癌相關。而且上述簡單的表格總結也提示,吸菸量同時和飲酒量和年齡相關。
64.5.1.2 我們先從分析吸菸習慣着手。將研究對象根據吸菸習慣分爲吸菸者 (tobacco_group = 1~4) 與非吸菸者 (tobacco_group = 0)。使用2 \(\times\) 2表格分析吸菸與否和患有食道癌與否之間的關係。使用公式手頭計算比值比 0dds ratio,和它的 95% 信賴區間。用統計軟件確認你的計算結果是否正確。
Oesophageal <- Oesophageal %>%
mutate(Tobacco_2 = as.factor(tobacco_group)) %>%
mutate(Tobacco_2 = fct_collapse(Tobacco_2,
NonSMker = "0",
SMker = c("1", "2", "3", "4")))
tab <- stat.table(index=list(Case = case,
Tobacco_gr = Tobacco_2),
contents=list(count(),
percent(Tobacco_2)),
data=Oesophageal, margins=TRUE)
print(tab, digits = 2)## ---------------------------------
## --------Tobacco_gr--------
## Case NonSMker SMker Total
## ---------------------------------
## 0 255.00 521.00 776.00
## 32.86 67.14 100.00
##
## 1 9.00 191.00 200.00
## 4.50 95.50 100.00
##
##
## Total 264.00 712.00 976.00
## 27.05 72.95 100.00
## ---------------------------------手動計算比值比和95%信賴區間:
## [1] 0.12218767## [1] 10.3870761 5.2353696 20.6081631所以,從表格推算的比值比 OR = 10.39;該比值比的對數對應的分佈方差估算爲 0.122。據此,該比值比的 95% CI爲 (5.24, 20.61)。有很強的證據表明,吸菸習慣的有無和患有食道癌之間有正關係。
用R驗證你的計算結果:
##
## case
## Tobacco_2 0 1 Total
## NonSMker 255 9 264
## SMker 521 191 712
## Total 776 200 976
##
## OR = 10.39
## 95% CI = 5.24, 20.61
## Chi-squared = 64.82, 1 d.f., P value = 0
## Fisher's exact test (2-sided) P value = 0用 Stata 做一樣的事情:
##
## . use "../backupfiles/oesophageal_data-1.dta"
##
## .
## . gen tobacco_2 = .
## (976 missing values generated)
##
## . replace tobacco_2 = 0 if tobacco_group == 0
## (264 real changes made)
##
## . replace tobacco_2 = 1 if tobacco_group >= 1
## (712 real changes made)
##
## .
## . mhodds case tobacco_2
##
## Maximum likelihood estimate of the odds ratio
## Comparing tobacco_2==1 vs. tobacco_2==0
##
## ----------------------------------------------------------------
## Odds Ratio chi2(1) P>chi2 [95% Conf. Interval]
## ----------------------------------------------------------------
## 10.387076 64.75 0.0000 5.109681 21.115085
## ----------------------------------------------------------------
##
## .值得注意的是,Stata 裏面的 mhodds 用的是不同於R的方法計算 95% 信賴區間的。
64.5.1.3 考慮使用邏輯回歸模型來獲取我們感興趣的比值比。請用數學語言寫下下列兩個模型的表達式:
- 吸菸與否爲結果變量,病例和對照的標記爲預測變量。
令 \(X\) 爲吸菸與否變量,\(D\) 爲病例/對照標記變量。
\[ \text{Pr}(X = 1 | D = d) = \frac{e^{\alpha^* + \beta d}}{1 + e^{\alpha^* + \beta d}} \]
- 病例和對照的標記爲結果變量,吸菸與否爲預測變量。
使用相同的標記來表達這個模型,另外,用 \(S = 1\) 表示該對象被選做本次研究的病例-對照樣本。所以,在下面的模型中,不要忘記我們還有一個條件變量,也就是該對象被選入本次實驗中。
\[ \text{Pr}(D = 1|X = x, S = 1) = \frac{e^{\lambda^* + \beta x}}{1 + e^{\lambda^* + \beta x}} \]
64.5.1.4 用你熟悉的統計軟件分別擬合上述兩個邏輯回歸模型。比較兩個解析報告的結果,並試着解釋他們各自的截距估計量的含義。用概率的數學表達式來說明二者的不同。
M1 <- glm(Tobacco_2 ~ case,
data = Oesophageal,
family = binomial(link = logit))
summary(M1); jtools::summ(M1, digits = 6, confint = TRUE, exp = TRUE)##
## Call:
## glm(formula = Tobacco_2 ~ case, family = binomial(link = logit),
## data = Oesophageal)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.49042 -1.49190 0.89264 0.89264 0.89264
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 0.714486 0.076426 9.3487 < 2.2e-16 ***
## case 2.340562 0.349515 6.6966 2.133e-11 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 1139.47 on 975 degrees of freedom
## Residual deviance: 1056.12 on 974 degrees of freedom
## AIC: 1060.12
##
## Number of Fisher Scoring iterations: 5| Observations | 976 |
| Dependent variable | Tobacco_2 |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| 𝛘²(1) | 83.357682 |
| Pseudo-R² (Cragg-Uhler) | 0.118838 |
| Pseudo-R² (McFadden) | 0.073154 |
| AIC | 1060.117214 |
| BIC | 1069.884140 |
| exp(Est.) | 2.5% | 97.5% | z val. | p | |
|---|---|---|---|---|---|
| (Intercept) | 2.043137 | 1.758910 | 2.373294 | 9.348719 | 0.000000 |
| case | 10.387076 | 5.235833 | 20.606336 | 6.696606 | 0.000000 |
| Standard errors: MLE |
M2 <- glm(case ~ Tobacco_2,
data = Oesophageal,
family = binomial(link = logit))
summary(M2); jtools::summ(M2, digits = 6, confint = TRUE, exp = TRUE)##
## Call:
## glm(formula = case ~ Tobacco_2, family = binomial(link = logit),
## data = Oesophageal)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -0.79035 -0.79035 -0.79035 -0.26338 2.59951
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -3.34404 0.33916 -9.8596 < 2.2e-16 ***
## Tobacco_2SMker 2.34056 0.34955 6.6959 2.144e-11 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 989.947 on 975 degrees of freedom
## Residual deviance: 906.590 on 974 degrees of freedom
## AIC: 910.59
##
## Number of Fisher Scoring iterations: 6| Observations | 976 |
| Dependent variable | case |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| 𝛘²(1) | 83.357682 |
| Pseudo-R² (Cragg-Uhler) | 0.128443 |
| Pseudo-R² (McFadden) | 0.084204 |
| AIC | 910.589629 |
| BIC | 920.356554 |
| exp(Est.) | 2.5% | 97.5% | z val. | p | |
|---|---|---|---|---|---|
| (Intercept) | 0.035294 | 0.018155 | 0.068612 | -9.859637 | 0.000000 |
| Tobacco_2SMker | 10.387076 | 5.235437 | 20.607897 | 6.695866 | 0.000000 |
| Standard errors: MLE |
你看到兩個模型計算出的比值比結果是完全一致的。這符合我們的預期。
其中,第一個模型的截距 \(\exp(\hat{\alpha*}) = 2.043\)。用概率的數學表達式表達爲: \(\exp(\hat{\alpha*}) =\text{Pr}(X=1 | D=0)/\text{Pr}(X = 0 | D = 0)\)。我們可以從原始的表格中的數據直接計算來獲得驗證:
\[ \text{Pr}(X=1|D=0) = 521/776 = 0.6714 \\ \text{Pr}(X=0|D=0) = 255/776 = 0.3286 \\ \Rightarrow \frac{\text{Pr}(X=1|D=0)}{\text{Pr}(X=0|D=0)} = \frac{0.6714}{0.3286} = 2.043 \]
在另外一個模型中的截距 \(\exp(\hat{\lambda}) = 0.035\)。從該模型的數學表達式出發,不難知道:
\[ \begin{aligned} \exp(\lambda^*) & = \frac{\text{Pr}(D = 1 | X = 0, S = 1)}{\text{Pr}(D = 0 | X = 0, S = 1)} \\ & = \frac{9 / 264}{255 / 264} = 0.03529 \end{aligned} \]
64.5.1.5 接下來我們將要分析酒精攝入量對上述關係可能存在的影響。請嘗試使用 Mantel-Haenszel 法來計算酒精攝入量調整後的吸菸與食道癌的比值比。調整了飲酒量之後的比值比發生了多大的變化?
##
## . use "../backupfiles/oesophageal_data-1.dta"
##
## .
## . gen tobacco_2 = .
## (976 missing values generated)
##
## . replace tobacco_2 = 0 if tobacco_group == 0
## (264 real changes made)
##
## . replace tobacco_2 = 1 if tobacco_group >= 1
## (712 real changes made)
##
## .
## . mhodds case tobacco_2, by(alcohol_grp)
##
## Maximum likelihood estimate of the odds ratio
## Comparing tobacco_2==1 vs. tobacco_2==0
## by alcohol_grp
##
## -------------------------------------------------------------------------------
## alcoho~p | Odds Ratio chi2(1) P>chi2 [95% Conf. Interval]
## ----------+--------------------------------------------------------------------
## 0-39 gra | . 17.31 0.0000 . .
## 40-79 gr | 9.552239 19.77 0.0000 2.82084 32.34690
## 80-119 g | 3.066667 4.73 0.0296 1.05865 8.88347
## 120+ gra | 12.941176 7.51 0.0061 1.20415 139.08120
## -------------------------------------------------------------------------------
##
## Mantel-Haenszel estimate controlling for alcohol_grp
## ----------------------------------------------------------------
## Odds Ratio chi2(1) P>chi2 [95% Conf. Interval]
## ----------------------------------------------------------------
## 8.587244 46.47 0.0000 4.079007 18.078115
## ----------------------------------------------------------------
##
## Test of homogeneity of ORs (approx): chi2(3) = 6.09
## Pr>chi2 = 0.1073
##
## .調整酒精攝入量之後,可見吸菸與食道癌的比值比 OR 從 10.39 略微降低到 8.59。與第一步的問題相結合,當時我們發現吸菸與飲酒之間有關聯,所以綜合以上信息可以認爲飲酒量是吸菸與食道癌關係的混雜因子 (confounder)。但是吸菸者與食道癌之間的強正關係 (strong positive association) 在調整了飲酒量之後依然是有統計學意義的。調整了飲酒量之後,吸菸者患有食道癌的比值 (odds) 高過不吸菸的人8倍以上。
64.5.1.6 請擬合合適的模型重複上述的分析,根據模型報告的結果尋找能夠評價調整了飲酒量以後的吸菸與患有食道癌之間關係的比值比及其信賴區間。解釋該模型的截距的含義是什麼。
M3 <- glm(case ~ Tobacco_2 + as.factor(alcohol_grp),
data = Oesophageal,
family = binomial(link = logit))
summary(M3); jtools::summ(M3, digits = 6, confint = TRUE, exp = TRUE)##
## Call:
## glm(formula = case ~ Tobacco_2 + as.factor(alcohol_grp), family = binomial(link = logit),
## data = Oesophageal)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.58458 -0.78012 -0.46294 -0.16370 2.53054
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -4.30590 0.38538 -11.1731 < 2.2e-16 ***
## Tobacco_2SMker 2.12652 0.35884 5.9260 3.103e-09 ***
## as.factor(alcohol_grp)1 1.14562 0.23664 4.8412 1.290e-06 ***
## as.factor(alcohol_grp)2 1.91822 0.26815 7.1535 8.459e-13 ***
## as.factor(alcohol_grp)3 3.09942 0.33503 9.2511 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 989.947 on 975 degrees of freedom
## Residual deviance: 786.564 on 971 degrees of freedom
## AIC: 796.564
##
## Number of Fisher Scoring iterations: 6| Observations | 976 |
| Dependent variable | case |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| 𝛘²(4) | 203.383008 |
| Pseudo-R² (Cragg-Uhler) | 0.295141 |
| Pseudo-R² (McFadden) | 0.205448 |
| AIC | 796.564303 |
| BIC | 820.981616 |
| exp(Est.) | 2.5% | 97.5% | z val. | p | |
|---|---|---|---|---|---|
| (Intercept) | 0.013489 | 0.006338 | 0.028708 | -11.173058 | 0.000000 |
| Tobacco_2SMker | 8.385601 | 4.150364 | 16.942686 | 5.926028 | 0.000000 |
| as.factor(alcohol_grp)1 | 3.144379 | 1.977466 | 4.999894 | 4.841238 | 0.000001 |
| as.factor(alcohol_grp)2 | 6.808843 | 4.025526 | 11.516593 | 7.153511 | 0.000000 |
| as.factor(alcohol_grp)3 | 22.185079 | 11.504870 | 42.779944 | 9.251133 | 0.000000 |
| Standard errors: MLE |
結論其實是一樣的。調整了飲酒量之後,吸菸者患有食道癌的比值高於非吸菸者 8 倍以上。另外,飲酒量的增加也與食道癌呈正相關。調整了吸菸量之後,飲酒量最多的人患有食道癌的比值比飲酒量最少的人高22倍以上。這個模型裏的截距可以用下列的數學表達式來解釋:
\[ \exp(\hat{\lambda^*}) = \frac{\text{Pr}(D = 1 | X = 0, \text{ alcohol } < 40 \text{ g/d}, S = 1)}{\text{Pr}(D = 0 | X = 0, \text{ alcohol } < 40 \text{ g/d}, S = 1)} \]
64.5.1.7 Mantel-Haenszel法計算的95%信賴區間和邏輯回歸模型給出的95%信賴區間估計相比有什麼不同?
二者不完全一樣。使用Mantel-Haenszel法計算的信賴區間範圍更寬。
64.5.1.8 接下來嘗試使用Mantel-Haenszel法和邏輯回歸模型各自進一步調整年齡。請觀察年齡對吸菸和患有食道癌之間的關係有何影響。比較兩種方法獲得的信賴區間估計。
- Mantel-Haenszel法
##
## . use "../backupfiles/oesophageal_data-1.dta"
##
## .
## . gen tobacco_2 = .
## (976 missing values generated)
##
## . replace tobacco_2 = 0 if tobacco_group == 0
## (264 real changes made)
##
## . replace tobacco_2 = 1 if tobacco_group >= 1
## (712 real changes made)
##
## .
## . mhodds case tobacco_2, by(alcohol_grp age_group)
##
## Maximum likelihood estimate of the odds ratio
## Comparing tobacco_2==1 vs. tobacco_2==0
## by alcohol_grp age_group
##
## note: only 17 of the 24 strata formed in this analysis contribute
## information about the effect of the explanatory variable
##
## -------------------------------------------------------------------------------
## alcoho~p age_gr~p | Odds Ratio chi2(1) P>chi2 [95% Conf. Interval]
## --------------------+----------------------------------------------------------
## 0-39 gra 1 | . . . . .
## 0-39 gra 2 | . 0.74 0.3897 . .
## 0-39 gra 3 | . 0.53 0.4669 . .
## 0-39 gra 4 | . 5.97 0.0145 . .
## 0-39 gra 5 | . 3.44 0.0637 . .
## 0-39 gra 6 | . 3.11 0.0779 . .
## 40-79 gr 1 | . . . . .
## 40-79 gr 2 | . 1.52 0.2172 . .
## 40-79 gr 3 | 8.595238 5.47 0.0194 0.98028 75.36422
## 40-79 gr 4 | . 7.06 0.0079 . .
## 40-79 gr 5 | 2.500000 1.10 0.2946 0.42406 14.73848
## 40-79 gr 6 | . 1.10 0.2943 . .
## 80-119 g 1 | . . . . .
## 80-119 g 2 | . . . . .
## 80-119 g 3 | 4.631579 2.07 0.1504 0.46444 46.18758
## 80-119 g 4 | 0.368421 0.73 0.3943 0.03362 4.03739
## 80-119 g 5 | 1.714286 0.17 0.6778 0.13070 22.48431
## 80-119 g 6 | . . . . .
## 120+ gra 1 | . 0.25 0.6171 . .
## 120+ gra 2 | . 0.67 0.4142 . .
## 120+ gra 3 | . . . . .
## 120+ gra 4 | . 7.34 0.0068 . .
## 120+ gra 5 | 0.000000 0.33 0.5637 . .
## 120+ gra 6 | . . . . .
## -------------------------------------------------------------------------------
##
## Mantel-Haenszel estimate controlling for alcohol_grp and age_group
## ----------------------------------------------------------------
## Odds Ratio chi2(1) P>chi2 [95% Conf. Interval]
## ----------------------------------------------------------------
## 6.973912 31.04 0.0000 3.146924 15.454919
## ----------------------------------------------------------------
##
## Test of homogeneity of ORs (approx): chi2(16) = 21.16
## Pr>chi2 = 0.1725
##
## .- 邏輯回歸模型
M4 <- glm(case ~ Tobacco_2 + as.factor(alcohol_grp) +
as.factor(age_group),
data = Oesophageal,
family = binomial(link = logit))
summary(M4); jtools::summ(M4, digits = 6, confint = TRUE, exp = TRUE)##
## Call:
## glm(formula = case ~ Tobacco_2 + as.factor(alcohol_grp) + as.factor(age_group),
## family = binomial(link = logit), data = Oesophageal)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.064050 -0.552410 -0.246922 -0.059923 2.877670
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -7.67141 1.10729 -6.9281 4.266e-12 ***
## Tobacco_2SMker 1.96635 0.37410 5.2562 1.471e-07 ***
## as.factor(alcohol_grp)1 1.34978 0.24982 5.4029 6.557e-08 ***
## as.factor(alcohol_grp)2 1.86788 0.28402 6.5766 4.813e-11 ***
## as.factor(alcohol_grp)3 3.51255 0.38314 9.1679 < 2.2e-16 ***
## as.factor(age_group)2 1.58061 1.08758 1.4533 0.1461325
## as.factor(age_group)3 3.36320 1.04676 3.2130 0.0013138 **
## as.factor(age_group)4 3.83362 1.04188 3.6795 0.0002337 ***
## as.factor(age_group)5 4.19618 1.04877 4.0010 6.306e-05 ***
## as.factor(age_group)6 4.37550 1.10517 3.9591 7.522e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 989.947 on 975 degrees of freedom
## Residual deviance: 686.554 on 966 degrees of freedom
## AIC: 706.554
##
## Number of Fisher Scoring iterations: 7| Observations | 976 |
| Dependent variable | case |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| 𝛘²(9) | 303.392825 |
| Pseudo-R² (Cragg-Uhler) | 0.419209 |
| Pseudo-R² (McFadden) | 0.306474 |
| AIC | 706.554486 |
| BIC | 755.389112 |
| exp(Est.) | 2.5% | 97.5% | z val. | p | |
|---|---|---|---|---|---|
| (Intercept) | 0.000466 | 0.000053 | 0.004082 | -6.928093 | 0.000000 |
| Tobacco_2SMker | 7.144524 | 3.431918 | 14.873381 | 5.256174 | 0.000000 |
| as.factor(alcohol_grp)1 | 3.856561 | 2.363465 | 6.292907 | 5.402894 | 0.000000 |
| as.factor(alcohol_grp)2 | 6.474554 | 3.710671 | 11.297108 | 6.576602 | 0.000000 |
| as.factor(alcohol_grp)3 | 33.533519 | 15.825306 | 71.056883 | 9.167852 | 0.000000 |
| as.factor(age_group)2 | 4.857925 | 0.576369 | 40.944982 | 1.453329 | 0.146132 |
| as.factor(age_group)3 | 28.881558 | 3.712057 | 224.712149 | 3.212957 | 0.001314 |
| as.factor(age_group)4 | 46.229816 | 5.998900 | 356.264618 | 3.679524 | 0.000234 |
| as.factor(age_group)5 | 66.431757 | 8.504718 | 518.909462 | 4.001039 | 0.000063 |
| as.factor(age_group)6 | 79.479504 | 9.110343 | 693.386792 | 3.959127 | 0.000075 |
| Standard errors: MLE |
從模型計算的結果來看,兩種方法其實點估計和信賴區間的估計值都很接近。不會有相互矛盾的結果。另外,Mantel-Haenszel法的計算在即使有些表格沒有人數的情況下也能穩健地給出計算結果。事實上我們可以認爲當存在數據分佈過於稀少 (sparse data issue) 的時候,Mantel-Haenszel法可能會更加可靠。
計算結果也表明,調整了年齡和飲酒量之後,吸菸者和食道癌的比值比又略降至7.14。年齡對酒精攝入和食道癌的比值比影響似乎較小,年齡本身與食道癌呈極強的正相關。
64.5.1.9 其實飲酒量和年齡本身是可以作爲連續型預測變量放入模型裏。重新加載含有連續變量的數據 oesophageal_data-2.dta後,把分類變量至換成連續型變量重新擬合前一個問題的模型.嘗試理解兩種策略的不同及相同之處。
Oesophageal2 <- read_dta("../backupfiles/oesophageal_data-2.dta")
Oesophageal2 <- Oesophageal2 %>%
mutate(Tobacco_2 = as.factor(tobacco_group)) %>%
mutate(Tobacco_2 = fct_collapse(Tobacco_2,
NonSMker = "0",
SMker = c("1", "2", "3", "4")))
M5 <- glm(case ~ Tobacco_2 + age + alcohol,
data = Oesophageal2,
family = binomial(link = logit))
summary(M5); jtools::summ(M5, digits = 6, confint = TRUE, exp = TRUE)##
## Call:
## glm(formula = case ~ Tobacco_2 + age + alcohol, family = binomial(link = logit),
## data = Oesophageal2)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.091909 -0.587340 -0.308824 -0.098386 2.751818
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -8.2302252 0.6511441 -12.6396 < 2.2e-16 ***
## Tobacco_2SMker 1.9275819 0.3663570 5.2615 1.429e-07 ***
## age 0.0646601 0.0081722 7.9122 2.528e-15 ***
## alcohol 0.0259834 0.0025424 10.2201 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 989.947 on 975 degrees of freedom
## Residual deviance: 702.994 on 972 degrees of freedom
## AIC: 710.994
##
## Number of Fisher Scoring iterations: 6| Observations | 976 |
| Dependent variable | case |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| 𝛘²(3) | 286.953775 |
| Pseudo-R² (Cragg-Uhler) | 0.399678 |
| Pseudo-R² (McFadden) | 0.289868 |
| AIC | 710.993536 |
| BIC | 730.527386 |
| exp(Est.) | 2.5% | 97.5% | z val. | p | |
|---|---|---|---|---|---|
| (Intercept) | 0.000266 | 0.000074 | 0.000955 | -12.639638 | 0.000000 |
| Tobacco_2SMker | 6.872871 | 3.351927 | 14.092297 | 5.261485 | 0.000000 |
| age | 1.066796 | 1.049845 | 1.084021 | 7.912217 | 0.000000 |
| alcohol | 1.026324 | 1.021222 | 1.031451 | 10.220096 | 0.000000 |
| Standard errors: MLE |
相同之處是,這兩種分析手法都在說明一件事,吸菸本身和患食道癌是高度相關的,這個關係在調整了年齡,和飲酒量之後依然存在。不同之處在與比值比在年齡和飲酒量使用連續變量時似乎又縮水了一些。值得注意的是,在回歸模型中決定使用連續型變量的時候,需要特別小心如何處理這些連續型預測變量。上面的模型其實還增加了另一個默認的前提條件,就是年齡,飲酒量在這個模型中默認和患有食道癌的比值的對數 (log-odds of being a case) 呈線性關係。但是,現實情況下這樣的默認前提可能不能得到滿足。也就是說在現實中,預測變量和結果變量的對數比值的關係很可能不是線性的。事實上你看 M4 的分析結果,飲酒量最多的那組的比值比飆得非常高。飲酒量的變量很可能就不適合用簡單地連續型變量模式放入模型中。但是使用連續型變量的另一個潛在的優點是模型中需要估計的參數個數相對較少。後面的章節會仔細討論連續型變量的處理。
64.5.2 Part 2
64.5.2.2 運用簡單的表格分析三個二進制變量之間可能存在的關係。
Log_prac <- read_dta("../backupfiles/logistic_data_part2.dta")
tab <- stat.table(index=list(y = y,
x = x),
contents=list(count(),
percent(x)),
data=Log_prac, margins=TRUE)
print(tab, digits = 2)## --------------------------------
## ------------x------------
## y 0 1 Total
## --------------------------------
## 0 1400.00 600.00 2000.00
## 70.00 30.00 100.00
##
## 1 600.00 1400.00 2000.00
## 30.00 70.00 100.00
##
##
## Total 2000.00 2000.00 4000.00
## 50.00 50.00 100.00
## --------------------------------tab <- stat.table(index=list(y = y,
w = w),
contents=list(count(),
percent(w)),
data=Log_prac, margins=TRUE)
print(tab, digits = 2)## --------------------------------
## ------------w------------
## y 0 1 Total
## --------------------------------
## 0 600.00 1400.00 2000.00
## 30.00 70.00 100.00
##
## 1 1400.00 600.00 2000.00
## 70.00 30.00 100.00
##
##
## Total 2000.00 2000.00 4000.00
## 50.00 50.00 100.00
## --------------------------------tab <- stat.table(index=list(x = x,
w = w),
contents=list(count(),
percent(w)),
data=Log_prac, margins=TRUE)
print(tab, digits = 2)## --------------------------------
## ------------w------------
## x 0 1 Total
## --------------------------------
## 0 1000.00 1000.00 2000.00
## 50.00 50.00 100.00
##
## 1 1000.00 1000.00 2000.00
## 50.00 50.00 100.00
##
##
## Total 2000.00 2000.00 4000.00
## 50.00 50.00 100.00
## --------------------------------y 和 x, w 兩者都有較強的相關性,但是 x, w 之間好像相互獨立沒有關係。
64.5.2.3 計算下列比值比:
y的x條件邊際比值比 (marginal odds ratio forygivenx)。
M6 <- glm(y ~ x,
data = Log_prac,
family = binomial(link = logit))
jtools::summ(M6, digits = 6, confint = TRUE, exp = TRUE)| Observations | 4000 |
| Dependent variable | y |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| 𝛘²(1) | 658.263028 |
| Pseudo-R² (Cragg-Uhler) | 0.202317 |
| Pseudo-R² (McFadden) | 0.118709 |
| AIC | 4890.914416 |
| BIC | 4903.502516 |
| exp(Est.) | 2.5% | 97.5% | z val. | p | |
|---|---|---|---|---|---|
| (Intercept) | 0.428571 | 0.389483 | 0.471582 | -17.364447 | 0.000000 |
| x | 5.444444 | 4.755707 | 6.232927 | 24.557037 | 0.000000 |
| Standard errors: MLE |
- 把數據分成兩個部分,一部分是
w = 0,令一部分w = 1。分別計算各個部分數據裏y的x條件邊際比值比。
M7 <- glm(y ~ x,
data = Log_prac[Log_prac$w == 0,],
family = binomial(link = logit))
jtools::summ(M7, digits = 6, confint = TRUE, exp = TRUE)| Observations | 2000 |
| Dependent variable | y |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| 𝛘²(1) | 406.996900 |
| Pseudo-R² (Cragg-Uhler) | 0.261072 |
| Pseudo-R² (McFadden) | 0.166566 |
| AIC | 2040.460308 |
| BIC | 2051.662113 |
| exp(Est.) | 2.5% | 97.5% | z val. | p | |
|---|---|---|---|---|---|
| (Intercept) | 1.000000 | 0.883416 | 1.131969 | -0.000000 | 1.000000 |
| x | 9.000000 | 7.073152 | 11.451755 | 17.875268 | 0.000000 |
| Standard errors: MLE |
M8 <- glm(y ~ x,
data = Log_prac[Log_prac$w == 1,],
family = binomial(link = logit))
jtools::summ(M8, digits = 6, confint = TRUE, exp = TRUE)| Observations | 2000 |
| Dependent variable | y |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| 𝛘²(1) | 406.996900 |
| Pseudo-R² (Cragg-Uhler) | 0.261072 |
| Pseudo-R² (McFadden) | 0.166566 |
| AIC | 2040.460308 |
| BIC | 2051.662113 |
| exp(Est.) | 2.5% | 97.5% | z val. | p | |
|---|---|---|---|---|---|
| (Intercept) | 0.111111 | 0.090373 | 0.136608 | -20.846420 | 0.000000 |
| x | 9.000000 | 7.073152 | 11.451755 | 17.875268 | 0.000000 |
| Standard errors: MLE |
數據在 w 變量分組中都得到了 OR = 9,的結果,說明 w 並非 x 與 y 之間關係的交互作用變量。
y的x和w的條件比值比
M9 <- glm(y ~ x + w,
data = Log_prac,
family = binomial(link = logit))
jtools::summ(M9, digits = 6, confint = TRUE, exp = TRUE)| Observations | 4000 |
| Dependent variable | y |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| 𝛘²(2) | 1472.256829 |
| Pseudo-R² (Cragg-Uhler) | 0.410570 |
| Pseudo-R² (McFadden) | 0.265502 |
| AIC | 4078.920616 |
| BIC | 4097.802765 |
| exp(Est.) | 2.5% | 97.5% | z val. | p | |
|---|---|---|---|---|---|
| (Intercept) | 1.000000 | 0.890953 | 1.122394 | 0.000000 | 1.000000 |
| x | 9.000000 | 7.590288 | 10.671532 | 25.279446 | 0.000000 |
| w | 0.111111 | 0.093707 | 0.131747 | -25.279446 | 0.000000 |
| Standard errors: MLE |
M9 的結果和預期的相同,調整了 w 之後,模型估計的 x 的比值比 OR = 9。和他們在 w 變量的各個分組數據的結果相同。
可以清楚的看到,沒調整 w 時,x 的比值比 OR = 5.44。但是 w 既不是 x, y 之間關係的混雜因子,也沒有有意義的交互作用。但是想要正確估計 x, y 之間的關係的話,不調整 w 計算獲得的比值比是錯誤的,這就是體現比值比不可壓縮性質的極好的例子。