第 80 章 聚類分析 Cluster analysis/unsupervised learning
目前爲止,在等級回歸模型部分中,我們接觸到的回歸模型和可能存在相互依賴性的數據,都是建立在我們能夠觀察到或者實驗設計上已知的數據層級結構的前提下的。這樣的層級可以是空間上的,或者時間上的。處在相同層級的研究對象之間存在相關性,換句話說就是:層級內部的對象之間,比起層級之間的對象具有更多的相似性。
但是,在許多情況下,我們其實是無法事先知道數據的內部層級(聚類)結構的。而且我們可能需要儘可能多的獲取數據,並且從測量的數據中學習。學習數據變量與變量之間的相關性(correlation),變量與變量之間的協方差(covariance),個體與個體之間的相似性,從而根據獲取的數據來判斷數據內部是否存在不同的層級結構。這樣的一種對數據結構進行探索的過程,在機器學習(maching learning)中也是常常使用的,它又被叫做非監督學習 (unsupervised learning)。
之所以把這類尋找數據分類分層結構的過程叫做非監督學習,其實,是爲了和現在越來越豐富,多到令人髮指的那些被歸類於監督學習(supervised learning)的方法作爲相互對照。在監督學習中,數據內部的分層,聚類結構是事先知道的,也就是事先能夠測量或者被定義好的。事先被定義好了的數據層級結構中,我們可以使用多元變量分析,來對某些個體的特徵加以分類,也就是給數據中的未知成員分配已知的分組的過程。
在醫學中常見的非監督學習過程實例之一是,對於一個(全部相同疾病的)隊列研究中的受試者進行了大量的生物標幟物(biomarker)的測量與收集,可以是血液樣本的 biomarker 的測量,也可以是每名受試者的全部DNA信息。研究者希望通過這些患者的信息對他們進行同一疾病不同等級(類別,或者進程)的分類。那麼研究者需要利用這些收集來的患者信息,建立一套儘可能完善的分類的系統。
另外一個例子是,我們收集了前列腺癌患者的前列腺組織,利用基因轉錄組學 (transcriptomics) 的方法測量了每名患者成千上萬的組織內基因表達。研究者希望通過這些數據來分析,提取,並且分辨這些前列腺癌患者中可能存在的分類,或者亞型。研究者也希望知道這些分析獲得的亞型,是否會和某些已知的癌症的亞型相似或者相重合。
在商業領域中,聚類分析也是不罕見的。例如你爲某商業公司工作,那麼食品供應商可能會上門來要求你把購買食物的顧客進行類別區分,從而提供給食物供應商們一些線索,讓他們能夠更加精準的定位廣告投放人羣。
在統計學,和機器學習領域中,有許多不同的手法,可以用來輔助建立這種分類的規則,它們通常又被叫做判別分析法(discriminant analysis methods)。我們這一章和下一章着重討論
- 聚類分析法 (cluster analysis)
- 主成分分析法 (principal component analysis)
80.1 聚類分析過程
聚類分析法是一種分析不同統計測量值之間相似/差異程度的描述性分析過程。
爲什麼我們總是想對具有相似性質的事物進行歸類?其實,對事物進行區分和歸類,或者打上一些標籤,是人類文明在學習並且理解周圍的世界,從而促進科學發展的核心問題之一。在原始社會,對相似事物進行歸類有時候甚至事關生死。例如人類最初需要判定某些食物的共同特徵,區分哪些是含有毒性的,哪類動物可能是兇猛殘忍的。我們從嬰兒時期開始學習語言,學習事物/事件/人物的名稱,這其實也是一個學習對周圍的世界進行區分的學習過程。古代希臘文明的先賢哲學家亞里士多德曾經主張,人類的本能之一,就是不停地想對這個我們生活的世界發生的事情看到的事物進行類別的區分,尋找相似的特徵,區別不一樣的性質。在生物學中,甚至有由亞里士多德的學生泰奧夫拉斯托斯(Theophrastos)創立的專門對生物進行分類的學科,生物分類學 (taxonomy),後被瑞典人生物學家卡爾林納斯 (Carl Linnaeus)進一步發揚光大。18世紀末,Michel Adanson又爲人類引入了多元分析(polythetic)的分類系統概念,取代了之前使用單一因素(monothetic)對事物進行簡單分類的思想。很顯然,生物分類學在人類文明史中扮演了重要的角色。你應該很容易能想到達爾文提出的進化論,就是建立在前人對動植物進行了事無鉅細的分類和整理的基礎之上建立起來的重大理論突破。俄國科學家門捷列夫發現化學元素週期性,並且製作出了世界上第一章元素週期表,也爲人類理解原子世界奠定了基石。
在對事物進行分類這個任務上,聚類分析(cluster analysis),和判別分析是相同的。有時候在已知對象的分類情況時我們仍然傾向於使用聚類分析的方法,用它來描述數據的一些特徵。同時也能有助於判定之後可能進行的判別分析是否準確。
簡單歸納,對分類描述過程進行量化的主要步驟有以下幾個:
對於採集來的樣本數據 (statistical sample),我們儘可能多的對它們的特徵變量進行測量。
根據第一步獲得的變量信息,定義一個能夠幫助我們判定對象與對象之間相似點或者不同程度的測量指標。
對這個測量指標制定一個區分的規則,或者叫做歸類的標準。
對樣本進行分類。
採集更多的樣本,對分類規則進行調整和完善。
80.1.1 連續型變量 continuous variables in cluster analysis
我們想象手裏的數據是一個矩陣 \(X\),它的維度是 \(n \times p\),用 \(x_{ik}\),來表示第 \(i\) 名觀察對象 \((i = 1, \dots, n)\) 的第 \(k\) 個變量 \((k = 1, \dots, p)\) 的值。如果這些被測量的變量全部都是連續型變量的話,每個變量可以被使用幾何學的形式表達的 \(p\) 個維度的其中一個平面上。當然,當維度超過3時,人類的無知大腦常常就無法進行有效的想象和推理,我們這裏使用簡單的三個變量,也就是三維空間來表示三個測量獲得的連續型變量:
例如我們測量了三名學生的身高,體重,以及前臂長。數據分別是:Angelo (190, 75, 30);Dimitris (170, 75, 25);Soren (170, 65, 30)。
圖 80.1: A physical 3D space showing measurements of three variables.
在這個三維立體空間,我們需要定義一個變量用於丈量點與點之間的距離。其中最自然的就是歐幾里德(Euclidean)幾何距離:
\[ d_{ij} = \{\sum_{k = 1}^p(x_{ik} - x_{jk})^2\}^{\frac{1}{2}} \]
- 歐幾里德幾何距離又被稱爲 L2 度量衡 (L2 metric)。按照這個距離的定義,那麼 Angelo 和 Dimitris 之間的歐幾里德幾何距離就是:
\[ \begin{aligned} & \{(190 - 175)^2 + (75 - 75)^2 + (30 - 25)^2 \}^{\frac{1}{2}} \\ = & \sqrt{15^2 + 0^2 + 5^2} \\ = & \sqrt{240} = 15.5 \end{aligned} \]
- 曼哈頓距離 (Manhattan distance):別名城市區塊度量衡 (cityblock metric),或者L1 度量衡
\[ d_{ij} = \sum_{k = 1}^p |x_{ik} - x_{jk}| \]
按照曼哈頓距離來定義的話,Angelo 和 Dimitris 之間的距離就是:
\[ |190 - 175| + |75 - 75| + |30 - 25| = 15 + 0 + 5 = 20 \]
後來人們發現上面提到的這兩種幾何學距離其實是閔科夫斯基度量衡 (Minkowski metric) 在 L=1 和 L=2 時的特殊情況。
閔科夫斯基度量衡的一般形式表達爲:
\[ d_{ij} = \{ \sum_{k = 1}^p |x_{ik} - x_{jk}|^\ell \}^\frac{1}{\ell} \]
閔科夫斯基度量衡試圖給差距較大的測量值之間增加權重用於區分彼此。不論是使用那種距離定義,這些測量距離的度量衡都具有如下的數學性質 (mathematical properties):
- 兩點之間的距離大於等於零, positivity
\(d_{ij} \geqslant 0\),如果 \(d_{ij} = 0\),那麼對於任何一個 \(k = 1, \dots, p\),它們都是相等的 \(x_{ik} = x_{jk}\)。 - 對稱性, symmetry
\(d_{ij} = d_{ji}\) - 三角形不等性, triangle inequality
\(d_{ij} \leqslant d_{ih} + d_{hj}\)
80.1.2 二分類或者分類型變量之間的距離 distances for binary/categorical variables
假如變量本身並不是連續型的,那麼閔科夫斯基度量衡並不適用,因爲二分量只能取0或者1。如下表所表示的,我們把 i,j 兩名對象的所有二分類變量進行下面的歸納總結:
| i/j | 1 | 0 |
|---|---|---|
| 1 | a | b |
| 0 | c | d |
其中,
- a 表示 i, j 兩名研究對象的二分類變量中,同時取 1 的變量的個數,
- b 表示 i, j 兩名研究對象的二分類變量中,i 取 1 但是 j 取 0 的變量的個數,
- c 表示 i, j 兩名研究對象的二分類變量中,j 取 1 但是 i 取 0 的變量的個數,
- d 表示 i, j 兩名研究對象的二分類變量中,同時取 0 的變量的個數。
根據這個總結表格,常用的表示兩個對象之間距離的數學度量是:
簡單匹配係數 (simple matching coefficient, SMC),單純地計算所有的變量之中互相不一致的變量所佔的百分比: \[d_{ij} = \frac{b + c}{a+b+c+d}\]
亞卡爾距離係數 (Jaccard coefficient),則是把簡單匹配係數的分母中,d 的部分拿掉:\[d_{ij} = \frac{b + c}{a + b + c}\]
另外值得注意的是,在測量二分類變量距離的時候,三角形不等性的特質不一定會得到滿足。 (Please note that in general for dichotomous variables, the triangle inequality does not hold.)
用來計算測量對象之間距離的方法,和度量衡其實層出不窮,這裏只是簡單介紹了幾種。其餘的還有比如說由 (Gower 1971) 提出的 Gower Index,該指標可以同時把測量有連續型變量和分類型變量,二分類變量等都包含進來。值得提醒的是,如果是討論非連續型測量值的對象距離,我們常常用它們之間的相似性(similarities) \(s_{ij}\),而不太關注異質性 (dissimilarities) \(d_{ij}\),但其是它們之間的簡單轉換關係就是 \(d_{ij} = 1 - s_{ij}\)。
80.1.3 定義分類方法
確定了用於衡量異質性 (dissimilarity) 距離的指標之後,我們就需要來定義分類的方法。首先把這個事先定下來的距離指標應用到我們的多元變量數據矩陣 (multivariate data matrix \(\mathbf{X}\)) (dimension: \(n\times p\), where n indicates number of people, p indicates number of observed variables). 獲得一個形狀爲 \(n\times n\) 的距離矩陣 \(\mathbf{D}\) (對應上面三條數學性質中的第二條,對稱性 \(d_{ij} = d_{ji}\))。獲得觀察對象的距離矩陣 \(\mathbf{D}\) 之後需要決定的就是如何給對象進行分組的策略。該分組策略需要能使觀察對象被分組後,組內的對象相對組外對象更加相似,或者組外對象相對組內對象更加不同 (a sensible strategy would be to look for sets of units such that all units in that set are relatively similar to each other but relatively different from all units outside that set)。所以,用於分組策略的算法要有一定的可行性,它還要能夠量化對象之間的相對相似性 (relative similarity) 從而能夠完成以下任務:
決定哪些人/對象被聚類到同一組中 (which pairs of units to join together into a cluster)
每次聚類過程完成以後,重複相同的策略和算法,也就是重新計算新組成的聚類和剩餘的對象之間的距離。
循環往復前兩個步驟直至全部的對象/個體都被分到各自的聚類 (cluster)。
事實上重複上述步驟,最終會把每個個體都分配到一個單獨的聚類中,也就是每個個體本身,那其實就跟沒有做聚類分析沒有區別,也沒有意義了。於是我們需要把聚類分析的過程通過圖形的方式展示出來。這樣的圖形被叫做樹狀圖 (dendrogram),可以在視覺上輔助我們做出要給對象分成多少個聚類的決定。在希臘語中(Greek),dendron 是樹的意思,樹狀圖的形狀常見的如下圖 (80.2) 所示,座標軸之一是所有的觀測對象的編號,另一個座標軸則是度量每個聚類或者觀測對象個體之間的距離。
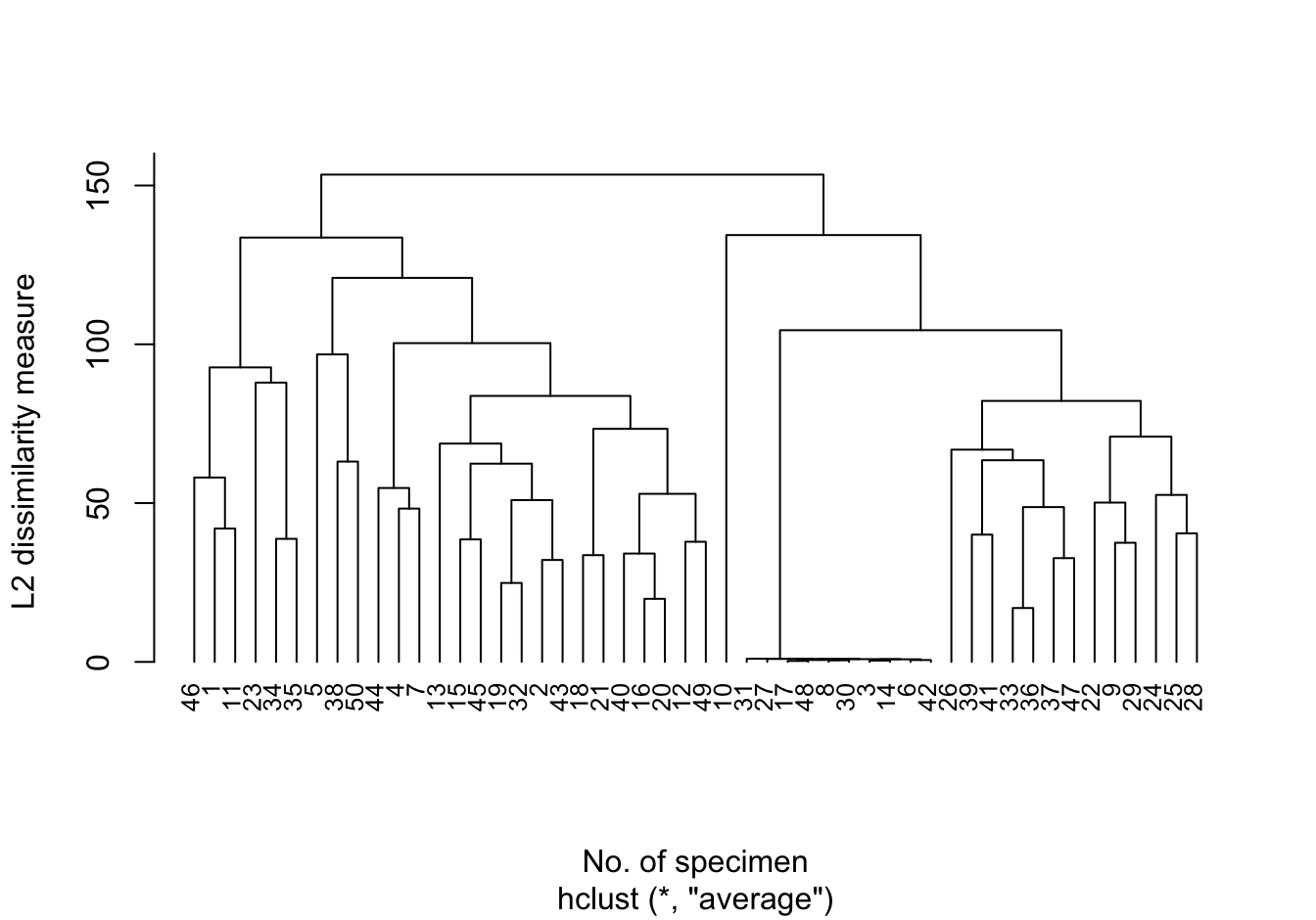
圖 80.2: Example of dendrogram vertically oriented, with 50 statistical units (average linkage method and Euclidean distance measure).
那麼回到之前如何決定聚類數量的問題上來,我們有兩種手段來輔助:
- 層級法 (hierarchical methods):聚合法,agglomerative; 或者分裂法, divisive。
- 分區算法 (partitioning methods)。
層級法中的聚合法 (agglomerative)是指,從聚類分析的開始階段,每個獨立的對象自成一個聚類 (cluster),所以起步於 n 個統計單位 (n statistical units),之後的每一步聚類過程則是將度量距離相近的對象合併成爲一個聚類,直至最終所有個體歸爲唯一一個聚類。所以可以想象爲從各個枝葉彙總到一個樹幹走向各個枝葉的過程。
層級法中的分裂法 (divisive)則是和聚合法的聚類方向反過來,它起始於將所有觀察對象視爲唯一一個聚類,之後每一步聚類過程是將和大部分對象不太相似的個體從聚類中分裂出去,直至最終每個獨立的對象自成一個聚類。所以可以想象成從一個樹幹走向枝葉的過程。
分裂法其實十分消耗計算機的運算能力,因爲當樣本量較大時,一個 \(k\) 種聚類的步驟就需要比較 \(2^{k-1} -1\) 種不同的分區之間的距離。