第 29 章 方差分析 Introduction to Analysis of Variance
29.1 背景
當我們用統計模型模擬真實數據的時候,我們常常會被問到這樣的問題:“兩個模型哪個能更好的擬合這個數據?”
本章我們先考慮簡單的情況,兩個模型互相比較時,其中一個稍微簡單些的模型使用的預測變量,同時也是另一個較複雜的模型的預測變量 (nested models)。所以,複雜模型的預測變量較多,而其中一個或者幾個預測變量又構成了新的較爲簡單的模型。這兩個模型之間的比較,就需要用到方差分析 Analysis of Variance (ANOVA)。
此處方差分析的原則是:如果複雜模型能夠更好的擬合真實實驗數據,那我們會認爲簡單模型無法解釋的大量殘差平方和,有效地被複雜模型解釋了。所以,這一原則下,可以推理,複雜模型計算獲得的殘差平方和,會顯著地小於簡單模型計算獲得的殘差平方和。ANOVA 就提供了這個殘差平方和變化的定量比較方法。
29.2 簡單線性迴歸模型的方差分析
其實從線性迴歸的第一章節開始,我們都在使用方差分析的思想。圖 27.1 數據的迴歸模型中,我們其實比較了以下兩個模型:
- 零假設模型:null model, 即認爲年齡和體重之間沒有任何關係 (水平直線);
- 替代模型: alternative model, 認爲年齡和體重之間有一定的線性關係 (擬合後的直線)。
## `geom_smooth()` using formula 'y ~ x'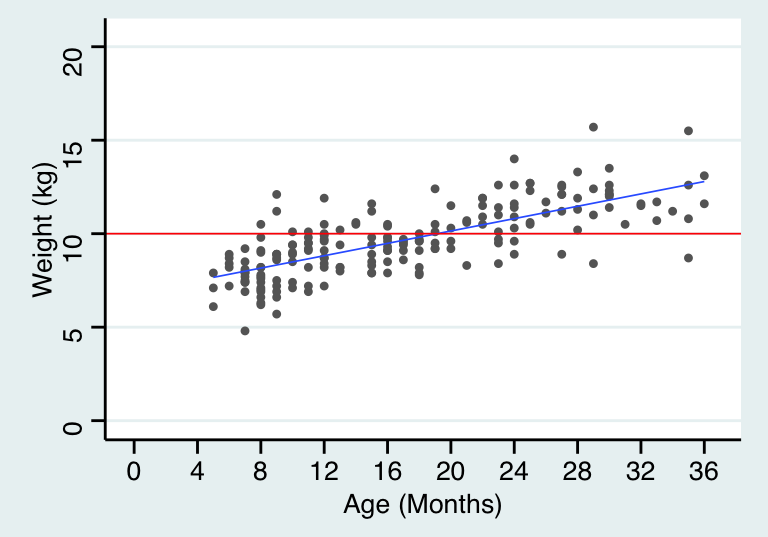
圖 29.1: NULL (red) and Alternative models (blue) for the data
29.2.1 兩個模型的參數估計
無論是零假設模型,還是替代假設模型,都需要通過最小化殘差來獲得其參數估計:
\[ SS_{RES} = \sum_{i=1}^n \hat\varepsilon^2= \sum_{i=1}^n(y_i-\hat y_i)^2 \]
替代假設模型,在線性迴歸第一部分 (Section 27.3.1) 已經提到過,均值方程是 \(E(Y|X=x) = \alpha+\beta x\),且這個方程的參數 \(\alpha, \beta\) 以及殘差方差 \(\sigma^2\) 的估計值計算公式也已經推導完成 (27.5) (27.6) (27.9)。
零假設模型,它的均值方程是 \(E(Y|X=x)=\alpha\)。所以需要將它的殘差最小化:
\[ SS_{RES} = \sum_{i=1}^n(y_i-\hat\alpha)^2 \]
由於 (27.5) :\(\hat\alpha=\bar{y}-\hat\beta\),所以 \(\hat\alpha = \bar{y}\)。
所以對於零假設模型來說:
\[ SS_{RES} = \sum_{i=1}^n(y_i-\bar{y})^2 =SS_{yy} \]
因此,沒有預測變量的零假設模型,它的殘差平方和,就等於因變量的平方和。
29.2.2 分割零假設模型的殘差平方和
ANOVA,方差分析的原則,其實就是將較簡單模型 (零假設模型) 的殘差平方和 \((SS_{RES_{NULL}})\),分割成下面兩個部分:
- 替代假設的複雜模型能夠說明的模型平方和 \((SS_{REG})\);
- 替代假設的複雜模型的殘差平方和 \((SS_{RES_{ALT}})\)。
用數學表達式表示爲:
\[ \begin{equation} \sum_{i=1}^n(y_i-\bar{y})^2 = \sum_{i=1}^n(\hat{y}-\bar{y})^2 + \sum_{i=1}^n(y_i-\hat{y}_i)^2 \\ SS_{RES_{NULL}}(SS_{yy}) = SS_{REG} + SS_{RES_{ALT}} \end{equation} \tag{29.1} \]
證明
\[ \begin{aligned} \sum_{i=1}^n(y_i-\bar{y})^2 &= \sum_{i=1}^n[(\hat{y}-\bar{y})+(y_i-\hat{y})]^2\\ &= \sum_{i=1}^n(\hat{y}-\bar{y})^2+\sum_{i=1}^n(y_i-\hat{y})^2+2\sum_{i=1}^n(\hat{y}_i-\bar{y})(y_i-\hat{y}) \\ &= SS_{REG} + SS_{RES_{ALT}} + 2\sum_{i=1}^n(\hat{y}_i-\bar{y})(y_i-\hat{y}) \end{aligned} \]
接下來就是要證明 \(\sum_{i=1}^n(\hat{y}_i-\bar{y})(y_i-\hat{y})=0\)
因爲公式 (28.1) \(\hat{y}_i=\bar{y}+\hat{\beta}(x_i-\bar{x})\) 所以公式變形如下:
\[ \begin{aligned} \sum_{i=1}^n(\hat{y}_i-\bar{y})(y_i-\hat{y}) &= \sum_{i=1}^n(\bar{y}+\hat\beta(x_i-\bar{x})-\bar{y})(y_i-\bar{y}-\hat\beta(x_i-\bar{x})) \\ &= \sum_{i=1}^n\hat\beta(x_i-\bar{x})[y_i-\bar{y}-\hat\beta(x_i-\bar{x})] \\ &= \hat\beta\sum_{i=1}^n(x_i-\bar{x})(y_i-\bar{y}) - \hat\beta^2\sum_{i=1}^n(x_i-\bar{x}) \\ &= \frac{S_{xy}}{S_{xx}}S_{xy} - (\frac{S_{xy}}{S_{xx}})^2SS_{xx}\\ &= 0 \\ \Rightarrow SS_{RES_{NULL}}(SS_{yy}) &= SS_{REG} + SS_{RES_{ALT}} \end{aligned} \]
29.2.3 \(R^2\) – 我的名字叫決定係數 coefficient of determination
在公式 (29.1) 中,因變量的平方和被分割成了兩個部分:\(SS_{REG}\) 迴歸模型能說明的部分,和 \(SS_{RES_{ALT}}\) 迴歸模型的殘差平方和。所以,我們定義迴歸模型能說明的部分,佔因變量平方和的百分比 \(\frac{SS_{REG}}{SS_{yy}}\),爲決定係數 \(R^2\)。
這個決定係數之前 (Section 28.5) 也出現過:
\[ \begin{equation} R^2 = \frac{SS_{REG}}{SS_{yy}} = \frac{\sum_{i=1}^n(\hat{y}_i-\bar{y})^2}{\sum_{i=1}^n(y_i-\bar{y})^2} = 1-\frac{\sum_{i=1}^n(y_i-\hat{y}_i)^2}{\sum_{i=1}^n(y_i-\bar{y})^2} \end{equation} \tag{29.2} \]
再一次回到數據 (27.1) 的線性迴歸來看:
growgam1 <- read_dta("../backupfiles/growgam1.dta")
Model <- lm(wt~age, data=growgam1)
print(summary(Model), digit=6)##
## Call:
## lm(formula = wt ~ age, data = growgam1)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.924182 -0.784889 0.007099 0.797468 4.067806
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 6.8375842 0.2100701 32.5491 < 2.22e-16 ***
## age 0.1653314 0.0111115 14.8793 < 2.22e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.274 on 188 degrees of freedom
## Multiple R-squared: 0.540782, Adjusted R-squared: 0.53834
## F-statistic: 221.392 on 1 and 188 DF, p-value: < 2.22e-16R 輸出的結果中最下面的部分 Multiple R-squared: 0.5408。我們就可以用“人話”來解釋其意義:假定年齡和體重成直線關係,那麼年齡解釋了這組數據中兒童體重變化 (平方和) 的 54%。
29.2.4 方差分析表格 the ANOVA table
一般情況下一個簡單線性迴歸,通過 ANOVA 對因變量平方和的分割,會被彙總成下面這樣的表格:
|
Source of Variation |
Sum of Squares |
Degrees of Freedom |
Mean Sum of Squares |
|---|---|---|---|
| Regression (model) | \(SS_{reg}\) | \(1\) | \(MS_{reg} = \frac{SS_{reg}}{1}\) |
| Residual | \(SS_{res}\) | \(n-2\) | \(MS_{res} = \frac{SS_{res}}{(n-2)}\) |
| Total | \(SS_{yy}\) | \(n-1\) | \(\frac{SS_{yy}}{(n-1)}\) |
表格中最右邊一列是平均平方和 (mean sum of squares)。它的定義是將平方和除以各自的自由度。其中殘差的平均平方和 \(MS_{RES}=\frac{SS_{RES}}{(n-2)}\) 是替代模型下殘差方差的無偏估計。總體平均平方和 (total mean sum of squares),則是零假設模型時的殘差方差估計。在 R 裏面也已經演示過多次 anova(model) 是調取方差分析表格的代碼:
## Analysis of Variance Table
##
## Response: wt
## Df Sum Sq Mean Sq F value Pr(>F)
## age 1 359.06320 359.06320 221.39203 < 2.22e-16 ***
## Residuals 188 304.90655 1.62184
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1注意到 R 省略掉第三行總體平方和的部分,不過其實也不太需要。檢驗統計量 F 的計算也很簡單,就是359.06320/1.62184=221.39。
29.2.5 用 ANOVA 進行假設檢驗
在 ANOVA 中使用的檢驗手段是 \(F\) 檢驗。這裏用 \(F\) 檢驗來比較模型解釋的因變量平方和部分 \((SS_{REG})\) 和這個模型不能解釋的殘差平方和部分 \(SS_{RES}\) 經過自由度校正以後比值的大小。
此時我們需要知道零假設和替代假設 \(\text{H}_0: \beta=0 \text{ v.s. H}_1: \beta\neq0\) 時,\(SS_{REG}, SS_{RES}\) 的分佈。
- 零假設和替代假設時,\(SS_{RES}\) 均服從自由度爲 \(n-2\) 的卡方分佈:
\[ \begin{equation} \text{Because } SS_{RES} = \sum_{i=1}^n \varepsilon \sim N(0, \sigma^2)\\ \frac{SS_{RES}}{\sigma^2} \sim \chi^2_{n-2} \end{equation} \tag{29.3} \]
- 零假設時, \(SS_{REG}\) 服從自由度爲 \(1\) 的卡方分佈,且與 \(SS_{RES}\) 相互獨立:
\[ \begin{equation} \frac{SS_{REG}}{\sigma^2} \sim \chi^2_1 \end{equation} \tag{29.4} \]
- 替代假設時,\(SS_{REG}\) 服從一個非中心化的卡方檢驗,且與 \(SS_{RES}\) 相互獨立:
\[ \begin{equation} SS_{REG} = \beta^2 SS_{xx} + U \text{ where }\frac{U}{\sigma^2} \sim \chi_1^2 \end{equation} \tag{29.5} \]
29.2.6 簡單線性迴歸時的 \(F\) 檢驗
如果兩個隨機變量各自服從相應自由度的卡方分佈,他們的每個元素的比值服從 \(F\) 分佈:
\[ A\sim \chi_a^2 \text{ and } B\sim \chi_b^2\\ \Rightarrow \frac{A/a}{B/b} \sim F_{a,b} \]
因此,目前爲止的推導過程我們也可以看到,在零假設條件下,\(MS_{REG}\) 和 \(MS_{RES}\) 的比值會服從 \(F\) 分佈,自由度爲 \((1, n-2)\):
\[ \begin{equation} F=\frac{SS_{REG}/1}{SS_{RES}/(n-2)} = \frac{MS_{REG}}{MS_{RES}} \sim F_{1,n-2} \end{equation} \tag{29.6} \]
在替代假設條件下 \((\text{H}_1: \beta\neq0)\),\(SS_{REG}\) 的期望值是 \(\sigma^2+\beta^2SS_{xx}\),所以替代假設條件下的 \(F\) 檢驗量總是會大於零假設時的 \(F\)。因此你可以看到,這是一個雙側檢驗 (\(\text{H}_0: \beta=0 \text{ v.s. H}_1: \beta\neq0\)),但是由於替代假設的 \(F\) 總是較大,所以只需要 \(F\) 的右半部分的概率密度積分 (單側 \(p\) 值)。
29.2.7 簡單線性迴歸時 \(F\) 檢驗和 \(t\) 檢驗的一致性
證明
\[ \begin{aligned} &F=\frac{SS_{REG}/1}{SS_{RES}/(n-2)} = \frac{SS_{REG}}{(SS_{yy}-SS_{REG})/(n-2)} \\ &\text{Since } r^2 = \frac{SS_{REG}}{SS_{yy}} \\ &F=(n-2)\frac{SS_{yy}r^2}{SS_{yy}-SS_{yy}r^2}=(n-2)(\frac{r^2}{1-r^2})=t^2 \end{aligned} \]
最後一步用到 (Section 28.6) 證明過的,迴歸係數檢驗統計量 \(t\),和 Pearson 相關係數 \(r\) 之間的關係。
29.3 分類變量用作預測變量時的 ANOVA
方差分析的應用是如此的廣泛,你可以在多重迴歸中使用,也可以在模型中有分類變量時使用,甚至是同時有連續性變量和分類變量的迴歸模型中得到應用。
之前也遇到過二分類變量的簡單線性迴歸模型,當時我們的做法是使用一個啞變量來表示一個二分類變量。同樣的方法也可以用到多組分類變量上來,然後繼續使用線性迴歸。
29.3.1 一個二分類預測變量
在前面的例子 (Section 27.7) 中也已經展示過,可以通過線性迴歸來分析一個二分類變量 (實驗組對照組),和一個連續型變量 (能直立行走時的兒童年齡)兩個變量之間的關係。而且其結果同兩樣本 \(t\) 檢驗的結果完全一致。
繼續回到之前用過的這個兒童行走數據 (表 27.1):
##
## Call:
## lm(formula = Age ~ Group, data = Walk)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.1250 -0.7375 -0.3750 0.3875 2.8750
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 10.12500 0.51223 19.7663 1.007e-08 ***
## Groupcontrol 2.22500 0.75977 2.9285 0.0168 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.255 on 9 degrees of freedom
## (1 observation deleted due to missingness)
## Multiple R-squared: 0.48795, Adjusted R-squared: 0.43105
## F-statistic: 8.5763 on 1 and 9 DF, p-value: 0.016797## Analysis of Variance Table
##
## Response: Age
## Df Sum Sq Mean Sq F value Pr(>F)
## Group 1 13.502 13.5017 8.5763 0.0168 *
## Residuals 9 14.169 1.5743
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1之前分析這個數據的時候也說明過了,這裏的迴歸係數 \(2.225\) 的含義是兩組之間均值的差異。而且注意看,這個迴歸係數是否爲零的檢驗統計量\((t-test)\)獲得的 \(p\) 值和 ANOVA 的檢驗結果 \((F-test)\) 也是一致的。正驗證了我們前面證明的結果。(Section 29.2.7)
29.3.2 一個模型,兩種表述
上面這個例子中,一個二分類的預測變量和一個因變量之間的關係,實際上可以用兩種數學模型來表達:
- 令 \(y_i, x_i\) 分別是第 \(i\) 名觀察對象的因變量 (“直立行走的年齡”),和預測變量 (“實驗組或者對照組”) \((i=1,\cdots,n)\)。那麼迴歸模型可以寫作:
\[ \begin{equation} y_i = \alpha+\beta x_i + \varepsilon_i, \text{ where } \varepsilon_i \sim NID(0, \sigma^2) \end{equation} \tag{29.7} \]
其中,
- \(x_i=0\) 時,表示第 \(i\) 名觀察對象在實驗組;
- \(x_i=1\) 時,表示第 \(i\) 名觀察對象在對照組。
在這樣的迴歸模型標記下,零假設和替代假設分別是 \(\text{H}_0: \beta=0 \text{ v.s. H}_1: \beta\neq0\)
- 另一種模型的表達方式,被叫做 ANOVA 表達方式。是如此描述上面的關係的:令 \(y_{ki}\) 表示第 \(i\) 名觀察對象,他在第 \(k\) 組 \((i=1,\cdots, n_k; k=1,2)\),此時的模型被寫作:
\[ \begin{equation} y_{ki} = \mu_k + \varepsilon_{ki}, \text{ where } \varepsilon_{ki} \sim NID(0, \sigma^2) \end{equation} \tag{29.8} \]
此時,\(\mu_k\) 表示第 \(k\) 組因變量的均值。零假設和替代假設分別是 \(\text{H}_0: \mu_k=\mu \text{ v.s. H}_1: \mu_k\neq\mu\)。這裏的 \(\mu\) 表示,每個組的平均值等於一個共同的均值 \(\mu\)。
29.3.3 分組變量的平方和
對於預測變量只有一個分組變量的模型,擬合後的數值就是兩組的因變量均值 \((\bar{y}_k)\)。在零假設條件下,兩組均值相等,均等於總體均值 \(\bar{y}\)。這就導致了,殘差平方和,模型平方和在分組變量的 ANOVA 分析時要使用與連續型變量不同的術語。
- 殘差平方和表示爲:
\[ \begin{equation} SS_{RES} = \sum_{k=1}^k\sum_{i=1}^{n_k} (y_{ki}-\bar{y}_k)^2 \end{equation} \tag{29.9} \]
其實這就是組內平方和 (within group sum of squares)。
- 模型平方和表示爲:
\[ \begin{equation} SS_{REG} = \sum_{k=1}^k\sum_{i=1}^{n_k}(\bar{y}_k-\bar{y})^2=\sum_{k=1}^kn_k(\bar{y}_k-\bar{y})^2 \end{equation} \tag{29.10} \]
其實這就是組間平方和 (between group sum of squares)
## Df Sum Sq Mean Sq F value Pr(>F)
## Group 1 13.5017 13.50170 8.57629 0.016797 *
## Residuals 9 14.1687 1.57431
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## 1 observation deleted due to missingness其實這跟之前的 anova(Model) 給出的結果完全一致。
##
## Bartlett test of homogeneity of variances
##
## data: Age by Group
## Bartlett's K-squared = 0.63, df = 1, p-value = 0.4FYI. 上面的代碼 bartlett.test() 利用的是另外一個叫做 Bartlett 檢驗法的方差比較公式。(在 STATA 的 oneway 命令中也會默認給出 Bartlett 檢驗的方差是否一致的檢驗結果)
29.3.4 簡單模型的分組變量大於兩組的情況
公式 (29.8), (29.9), 和 (29.10) 在兩組以上分組變量作預測變量時也是適用的。但是當組數爲 \(K\) 時,組內平方和 (殘差平方和 \(SS_{RES}\)) 的自由度需要修改成 \(n-K\) (這是因爲模型中使用了 \(K\) 個參數)。此時方差分析 ANOVA 的彙總表格就變爲了下面這樣:
|
Source of variation |
Sum of Squares |
Degrees of Freedom |
Mean Sum of Squares |
|---|---|---|---|
| Between groups | \(SS_{between}\) | \(K-1\) | \(\frac{SS_{between}}{(K-1)}\) |
| Within groups | \(SS_{within}\) | \(n-K\) | \(\frac{SS_{within}}{(n-K)}\) |
| Total | \(SS_{yy}\) | \(n-1\) | \(\frac{SS_{yy}}{(n-1)}\) |
此時,檢驗統計量 \(F\) 的計算公式爲:
\[ \begin{equation} F=\frac{SS_{between}/(K-1)}{SS_{within}/(n-K)} \sim F_{(K-1),(n-K)} \end{equation} \tag{29.11} \]
在解釋兩組以上分組變量的分析結果時,要注意的是如果 \(p\) 值很小,檢驗結果告訴我們的是,各組中因變量的均值不全相等,而不是全部都不相等。其實就是,即使做了這個檢驗,我們也不知道到底那兩組之間是有差異的。如果此時我們發現結果提示均值不全相等,通常我們還會再作進一步的分析,使用類似成對比較法等等 (以後再繼續詳述)。不過提前要記住,如果使用成對比較法時 (pair-wise comparisons),多重比較的問題 (multiple comparisons)會凸顯出來,主要的結果是增加統計檢驗的假陽性 (false-positive) 概率,此時再繼續使用 \(p<0.05\) 作爲統計學意義的標準則是不妥當的。