對數似然比 Log-likelihood ratio
對數似然比 Log-likelihood ratio
對數似然比的想法來自於將對數似然方程圖形的 \(y\) 軸重新調節 (rescale) 使之最大值爲零。這可以通過計算該分佈方程的對數似然比 (log-likelihood ratio) 來獲得:
\[llr(\theta)=\ell(\theta|data)-\ell(\hat{\theta}|data)\]
由於 \(\ell(\theta)\) 的最大值在 \(\hat{\theta}\) 時, 所以,\(llr(\theta)\) 就是個當 \(\theta=\hat{\theta}\) 時取最大值,且最大值爲零的方程。很容易理解我們叫這個方程爲對數似然比,因爲這個方程就是將似然比 \(LR(\theta)=\frac{L(\theta)}{L(\hat{\theta})}\) 取對數而已。
之前我們也確證了,不包含我們感興趣的參數的方程部分可以忽略掉。還是用上一節 10人中4人患病的例子:
\[L(\pi|X=4)=\binom{10}{4}\pi^4(1-\pi)^{10-4}\\ \Rightarrow \ell(\pi)=log[\pi^4(1-\pi)^{10-4}]\\ \Rightarrow llr(\pi)=\ell(\pi)-\ell(\hat{\pi})=log\frac{\pi^4(1-\pi)^{10-4}}{0.4^4(1-0.4)^{10-4}}\]
其實由上也可以看出 \(llr(\theta)\) 只是將對應的似然方程的 \(y\) 軸重新調節了一下而已。形狀是沒有改變的:
par(mfrow=c(1,2))
x <- seq(0,1,by=0.001)
y <- (x^4)*((1-x)^6)/(0.4^4*0.6^6)
z <- log((x^4)*((1-x)^6))-log(0.4^4*0.6^6)
plot(x, y, type = "l", ylim = c(0,1.1),yaxt="n",
frame.plot = FALSE, ylab = "LR(\U03C0)", xlab = "\U03C0")
axis(2, at=seq(0,1, 0.2), las=2)
title(main = "Binomial likelihood ratio")
abline(h=1.0, lty=2)
segments(x0=0.4, y0=0, x1=0.4, y1=1, lty = 2)
plot(x, z, type = "l", ylim = c(-10, 1), yaxt="n", frame.plot = FALSE,
ylab = "llr(\U03C0)", xlab = "\U03C0" )
axis(2, at=seq(-10, 0, 2), las=2)
title(main = "Binomial log-likelihood ratio")
abline(h=0, lty=2)
segments(x0=0.4, y0=-10, x1=0.4, y1=0, lty = 2)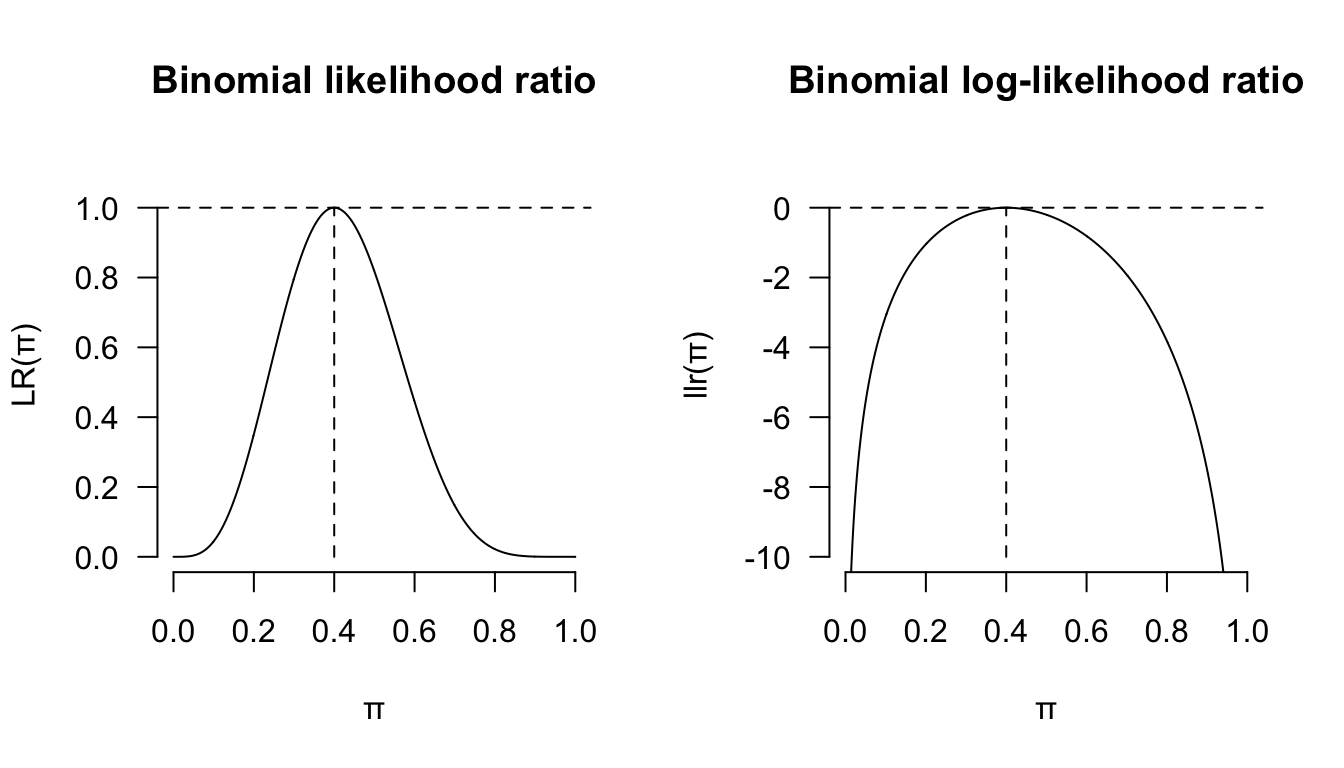
正態分佈數據的最大似然和對數似然比
假設單個樣本 \(y\) 是來自一組服從正態分佈數據的觀察值:\(Y\sim N(\mu, \tau^2)\)
那麼有:
\[ \begin{aligned} f(y|\mu) &= \frac{1}{\sqrt{2\pi\tau^2}}e^{(-\frac{1}{2}(\frac{y-\mu}{\tau})^2)} \\ \Rightarrow L(\mu|y) &=\frac{1}{\sqrt{2\pi\tau^2}}e^{(-\frac{1}{2}(\frac{y-\mu}{\tau})^2)} \\ \Rightarrow \ell(\mu)&=log(\frac{1}{\sqrt{2\pi\tau^2}})-\frac{1}{2}(\frac{y-\mu}{\tau})^2\\ omitting&\;terms\;not\;in\;\mu \\ &= -\frac{1}{2}(\frac{y-\mu}{\tau})^2 \\ \Rightarrow \ell^\prime(\mu) &= 2\cdot[-\frac{1}{2}(\frac{y-\mu}{\tau})\cdot\frac{-1}{\tau}] \\ &=\frac{y-\mu}{\tau^2} \\ let \; \ell^\prime(\mu) &= 0 \\ \Rightarrow \frac{y-\mu}{\tau^2} &= 0 \Rightarrow \hat{\mu} = y\\ \because \ell^{\prime\prime}(\mu) &= \frac{-1}{\tau^2} < 0 \\ \therefore \hat{\mu} &= y \Rightarrow \ell(\hat{\mu}=y)_{max}=0 \\ llr(\mu)&=\ell(\mu)-\ell(\hat{\mu})=\ell(\mu)\\ &=-\frac{1}{2}(\frac{y-\mu}{\tau})^2 \end{aligned} \]
\(n\) 個獨立正態分佈樣本的對數似然比
假設一組觀察值來自正態分佈 \(X_1,\cdots,X_n\stackrel{i.i.d}{\sim}N(\mu,\sigma^2)\),先假設 \(\sigma^2\) 已知。將觀察數據 \(x_1,\cdots, x_n\) 標記爲 \(\underline{x}\)。 那麼:
\[ \begin{aligned} L(\mu|\underline{x}) &=\prod_{i=1}^nf(x_i|\mu)\\ \Rightarrow \ell(\mu|\underline{x}) &=\sum_{i=1}^nlogf(x_i|\mu)\\ &=\sum_{i=1}^n[-\frac{1}{2}(\frac{x_i-\mu}{\sigma})^2]\\ &=-\frac{1}{2\sigma^2}\sum_{i=1}^n(x_i-\mu)^2\\ &=-\frac{1}{2\sigma^2}[\sum_{i=1}^n(x_i-\bar{x})^2+\sum_{i=1}^n(\bar{x}-\mu)^2]\\ omitting&\;terms\;not\;in\;\mu \\ &=-\frac{1}{2\sigma^2}\sum_{i=1}^n(\bar{x}-\mu)^2\\ &=-\frac{n}{2\sigma^2}(\bar{x}-\mu)^2 \\ &=-\frac{1}{2}(\frac{\bar{x}-\mu}{\sigma/\sqrt{n}})^2\\ \because \ell(\hat{\mu}) &= 0 \\ \therefore llr(\mu) &= \ell(\mu)-\ell(\hat{\mu}) = \ell(\mu) \end{aligned} \]
\(n\) 個獨立正態分佈樣本的對數似然比的分佈
假設我們用 \(\mu_0\) 表示總體均數這一參數的值。要注意的是,每當樣本被重新取樣,似然,對數似然方程,對數似然比都隨着觀察值而變 (即有自己的分佈)。
考慮一個服從正態分佈的單樣本 \(Y\): \(Y\sim N(\mu_0,\tau^2)\)。那麼它的對數似然比:
\[llr(\mu_0|Y)=\ell(\mu_0)-\ell(\hat{\mu})=-\frac{1}{2}(\frac{Y-\mu_0}{\tau})^2\]
根據卡方分佈的定義:
\[\because \frac{Y-\mu_0}{\tau}\sim N(0,1)\\ \Rightarrow (\frac{Y-\mu_0}{\tau})^2 \sim \mathcal{X}_1^2\\ \therefore -2llr(\mu_0|Y) \sim \mathcal{X}_1^2\]
所以,如果有一組服從正態分佈的觀察值:\(X_1,\cdots,X_n\stackrel{i.i.d}{\sim}N(\mu_0,\sigma^2)\),且 \(\sigma^2\) 已知的話:
\[-2llr(\mu_0|\bar{X})\sim \mathcal{X}_1^2\]
根據中心極限定理,可以將上面的結論一般化:似然比信賴區間
如果樣本量 \(n\) 足夠大 (通常應該大於 \(30\)),根據上面的定理:
\[-2llr(\theta_0)=-2\{\ell(\theta_0)-\ell(\hat{\theta})\}\sim \mathcal{X}_1^2\]
所以:
\[Prob(-2llr(\theta_0)\leqslant \mathcal{X}_{1,0.95}^2=3.84) = 0.95\\ \Rightarrow Prob(llr(\theta_0)\geqslant-3.84/2=-1.92) = 0.95\]
故似然比的 \(95\%\) 信賴區間就是能夠滿足 \(llr(\theta)=-1.92\) 的兩個 \(\theta\) 值。
以二項分佈數據爲例
繼續用本文開頭的例子:
\[llr(\pi)=\ell(\pi)-\ell(\hat{\pi})=log\frac{\pi^4(1-\pi)^{10-4}}{0.4^4(1-0.4)^{10-4}}\]
如果令 \(llr(\pi)=-1.92\) 在代數上可能較難獲得答案。然而從圖形上,如果我們在 \(y=-1.92\) 畫一條橫線,和該似然比方程曲線相交的兩個點就是我們想要求的信賴區間的上限和下限:
x <- seq(0,1,by=0.001)
z <- log((x^4)*((1-x)^6))-log(0.4^4*0.6^6)
plot(x, z, type = "l", ylim = c(-10, 1), yaxt="n", frame.plot = FALSE,
ylab = "llr(\U03C0)", xlab = "\U03C0" )
axis(2, at=seq(-10, 0, 2), las=2)
abline(h=0, lty=2)
abline(h=-1.92, lty=2)
segments(x0=0.15, y0=-12, x1=0.15, y1=-1.92, lty = 2)
segments(x0=0.7, y0=-12, x1=0.7, y1=-1.92, lty = 2)
axis(1, at=c(0.15,0.7))
text(0.9, -1, "-1.92")
arrows(0.8, -1.92, 0.8, 0, lty = 1, length = 0.08)
arrows( 0.8, 0, 0.8, -1.92, lty = 1, length = 0.08)
title(main = "Log-likelihood ratio for binomial example, \n with 95% likelihood confidence interval shown")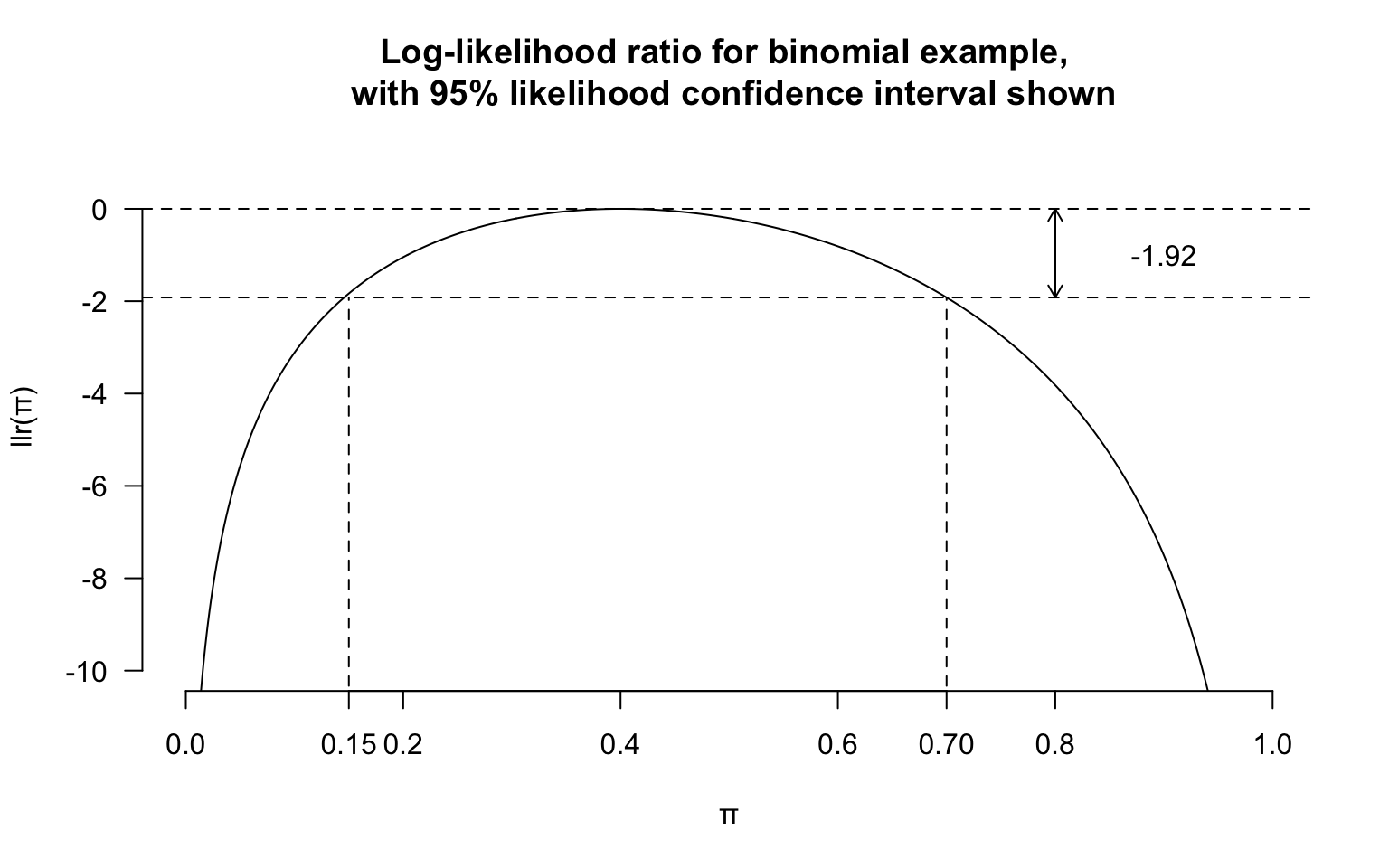
從上圖中可以讀出,\(95\%\) 對數似然比信賴區間就是 \((0.15, 0.7)\)
以正態分佈數據爲例
本文前半部分證明過, \(X_1,\cdots,X_n\stackrel{i.i.d}{\sim}N(\mu,\sigma^2)\),先假設 \(\sigma^2\) 已知。將觀察數據 \(x_1,\cdots, x_n\) 標記爲 \(\underline{x}\)。 那麼:
\[llr(\mu|\underline{x}) = \ell(\mu|\underline{x})-\ell(\hat{\mu}) = \ell(\mu|\underline{x}) \\ =-\frac{1}{2}(\frac{\bar{x}-\mu}{\sigma/\sqrt{n}})^2\]
很顯然,這是一個關於 \(\mu\) 的二次方程,且最大值在 MLE \(\hat{\mu}=\bar{x}\) 時取值 \(0\)。所以可以通過對數似然比法求出均值的 \(95\%\) 信賴區間公式:
\[-2\times[-\frac{1}{2}(\frac{\bar{x}-\mu}{\sigma/\sqrt{n}})^2]=3.84\\ \Rightarrow L=\bar{x}-\sqrt{3.84}\frac{\sigma}{\sqrt{n}} \\ U=\bar{x}+\sqrt{3.84}\frac{\sigma}{\sqrt{n}} \\ note: \;\sqrt{3.84}=1.96\]
注意到這和我們之前求的正態分佈均值的信賴區間公式完全一致。
Exercise
Q1
- 假設十個對象中有三人死亡,用二項分佈模型來模擬這個例子,求這個例子中參數 \(\pi\) 的似然方程和圖形 (likelihood) ?
解
\(\begin{aligned} L(\pi|3) &= \binom{10}{3}\pi^3(1-\pi)^{10-3} \\ omitting\;&terms\;not\;in\;\mu \\ \Rightarrow \ell(\pi|3) &= log[\pi^3(1-\pi)^7] \\ &= 3log\pi+7log(1-\pi)\\ \Rightarrow \ell^\prime(\pi|3)&= \frac{3}{\pi}-\frac{7}{1-\pi} \\ let \; \ell^\prime& =0\\ &\frac{3}{\pi}-\frac{7}{1-\pi} = 0 \\ &\frac{3-10\pi}{\pi(1-\pi)} = 0 \\ \Rightarrow MLE &= \hat\pi = 0.3 \end{aligned}\)
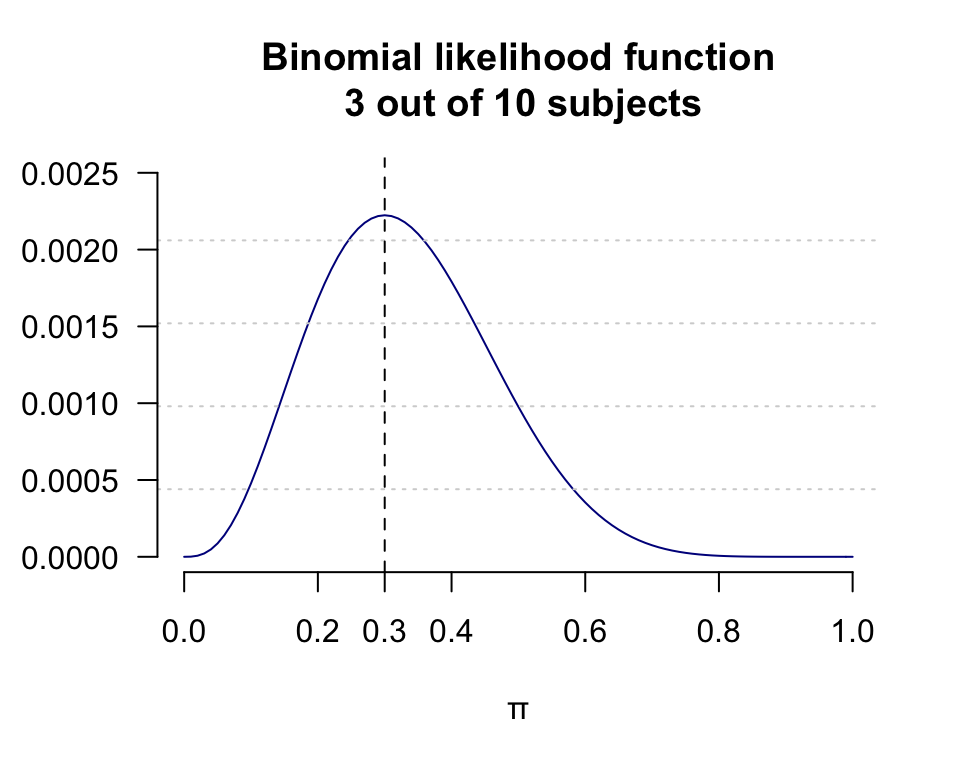
- 計算似然比,並作圖,注意方程圖形未變,\(y\) 軸的變化;取對數似然比,並作圖
LR <- L/max(L) ; head(LR)## [1] 0.0000000000 0.0004191759 0.0031233631 0.0098110584 0.0216286076
## [6] 0.0392577320plot(pi, LR, type = "l", ylim = c(0, 1),yaxt="n", col="darkblue",
frame.plot = FALSE, ylab = "", xlab = "\U03C0")
grid(NA, 5, lwd = 1)
axis(2, at=seq(0,1,0.2), las=2)
title(main = "Binomial likelihood ratio function\n 3 out of 10 subjects")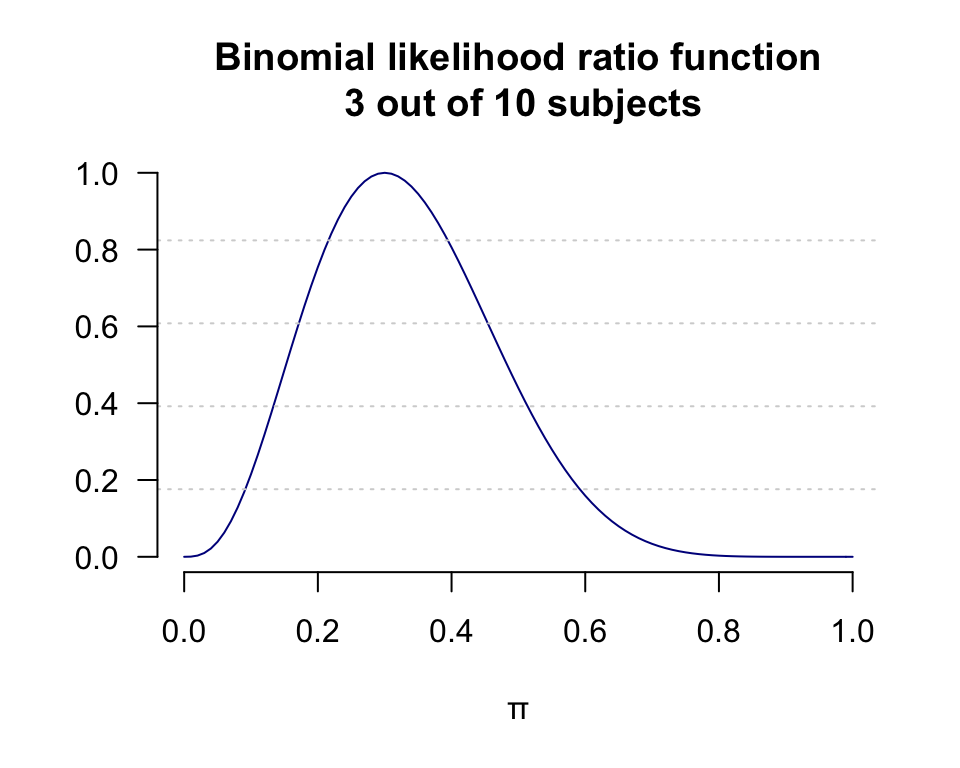
logLR <- log(L/max(L))
plot(pi, logLR, type = "l", ylim = c(-4, 0),yaxt="n", col="darkblue",
frame.plot = FALSE, ylab = "", xlab = "\U03C0")
grid(NA, 5, lwd = 1)
axis(2, at=seq(-4,0,1), las=2)
title(main = "Binomial log-likelihood ratio function\n 3 out of 10 subjects")
abline(h=-1.92, lty=1, col="red")
axis(4, at=-1.92, las=0)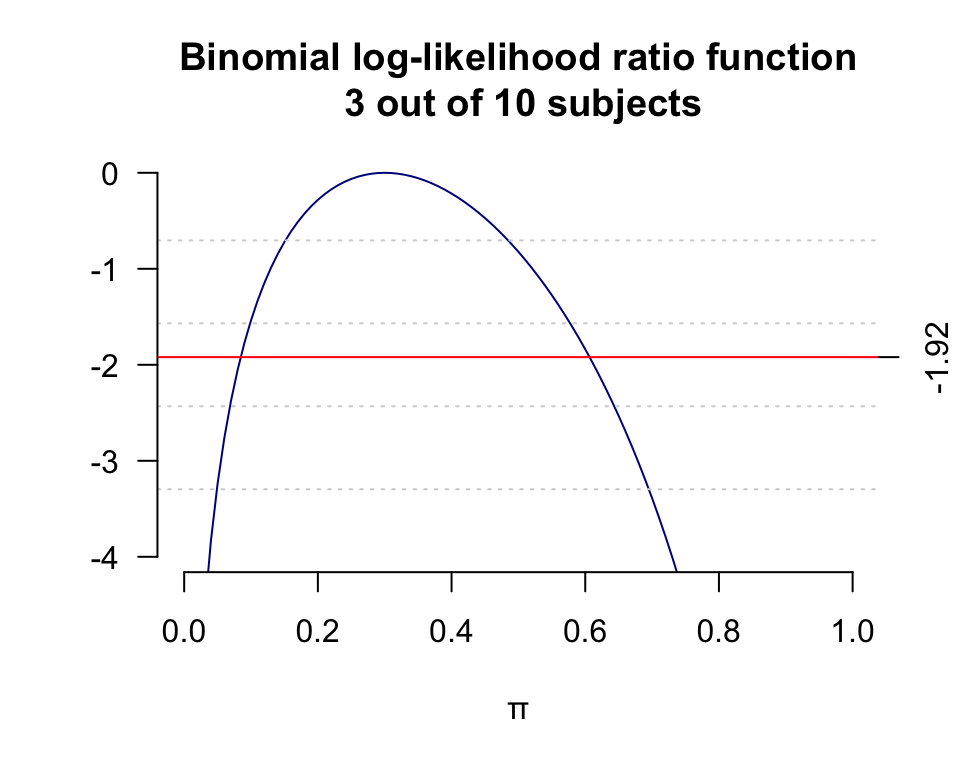
Q2
- 與上面用同樣的模型,但是觀察人數變爲 \(100\) 人 患病人數爲 \(30\) 人,試作對數似然比方程之圖形,與上圖對比:
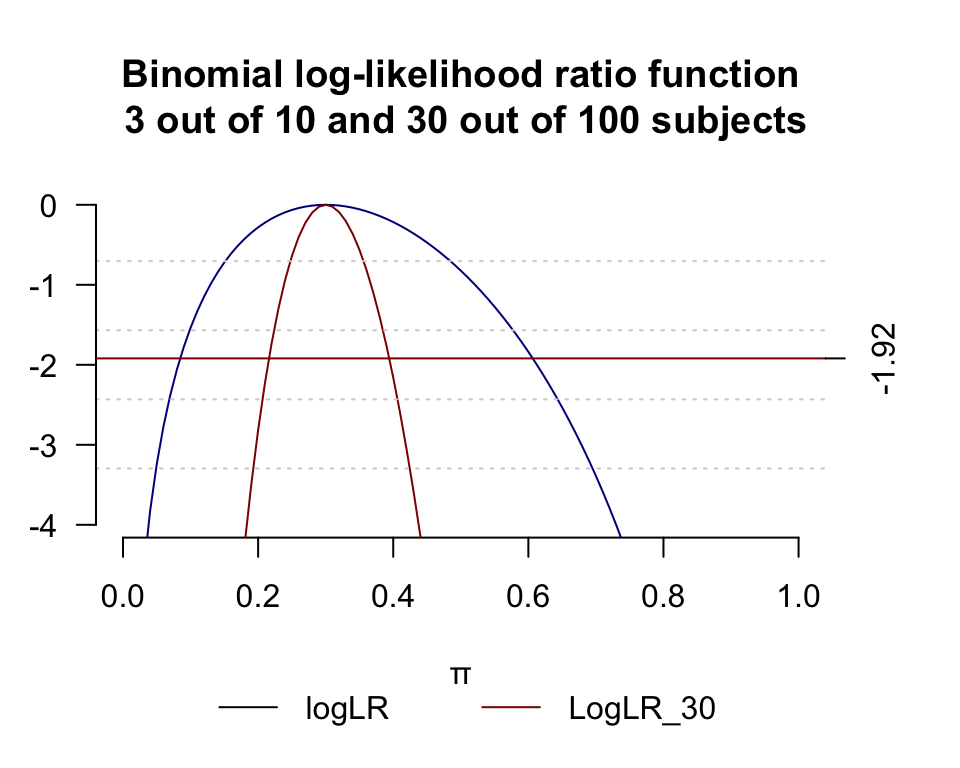
可以看出,兩組數據的 MLE 都是一致的, \(\hat\pi=0.3\),但是對數似然比方程圖形在 樣本量爲 \(n=100\) 時比 \(n=10\) 時窄很多,由此產生的似然比信賴區間也就窄很多(精確很多)。所以對數似然比方程的曲率(二階導數),反映了觀察獲得數據提供的對總體參數 \(\pi\) 推斷過程中的信息量。而且當樣本量較大時,對數似然比方程也更加接近左右對稱的二次方程曲線。
Q3
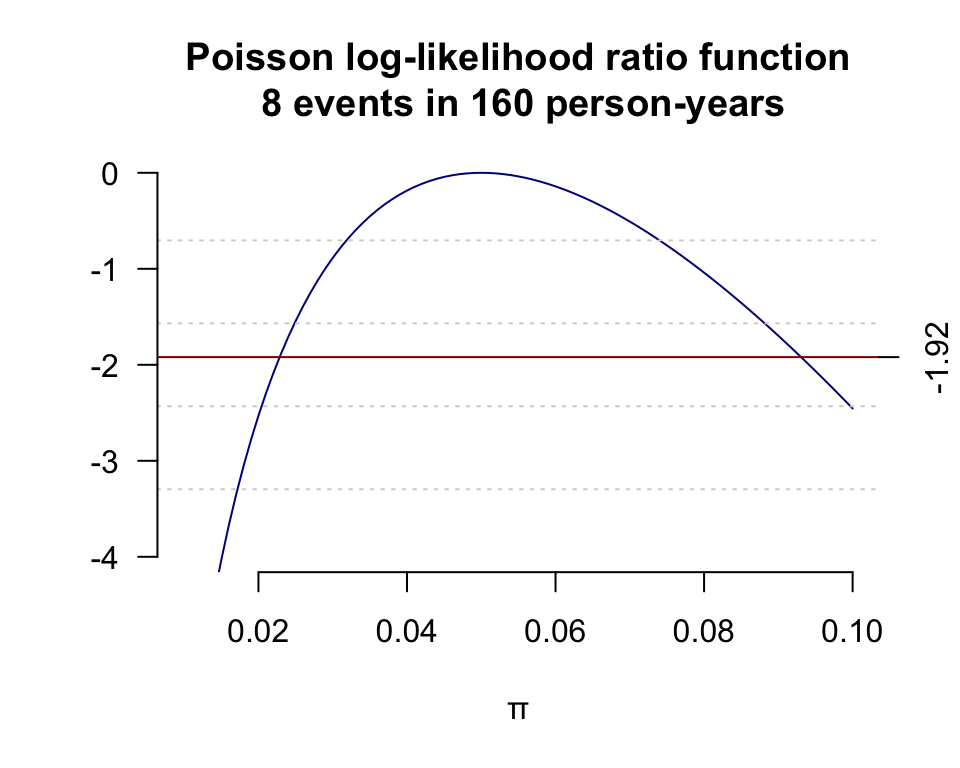
在一個實施了160人年的追蹤調查中,觀察到8個死亡案例。使用泊松分佈模型,繪製對數似然比方程圖形,從圖形上目視推測極大似然比的 \(95\%\) 信賴區間。
解
\(\begin{aligned} d = 8, \;p &= 160\; person\cdot year \\ \Rightarrow D\sim Poi(\mu &=\lambda p) \\ L(\lambda|data) &= Prob(D=d=8) \\ &= e^{-\mu}\frac{\mu^d}{d!} \\ &= e^{-\lambda p}\frac{\lambda^d p^d}{d!} \\ omitting&\;terms\;not\;in\;\lambda \\ &= e^{-\lambda p}\lambda^d \\ \Rightarrow \ell(\lambda|data)&= log(e^{-\lambda p}\lambda^d) \\ &= d\cdot log(\lambda)-\lambda p \\ & = 8\times log(\lambda) - 160\times\lambda \end{aligned}\)
| lambda | LogLR |
|---|---|
| 0.010 | -6.4755033 |
| 0.011 | -5.8730219 |
| 0.012 | -5.3369308 |
| 0.013 | -4.8565892 |
| 0.014 | -4.4237254 |
| 0.015 | -4.0317824 |
| 0.016 | -3.6754743 |
| 0.017 | -3.3504773 |
| 0.018 | -3.0532100 |
| 0.019 | -2.7806722 |
| 0.020 | -2.5303259 |
| 0.021 | -2.3000045 |
| 0.022 | -2.0878444 |
| 0.023 | -1.8922303 |
| 0.024 | -1.7117534 |
| 0.025 | -1.5451774 |
| 0.026 | -1.3914117 |
| 0.027 | -1.2494891 |
| 0.028 | -1.1185480 |
| 0.029 | -0.9978174 |
| 0.030 | -0.8866050 |
| 0.031 | -0.7842864 |
| 0.032 | -0.6902968 |
| 0.033 | -0.6041236 |
| 0.034 | -0.5252998 |
| 0.035 | -0.4533996 |
| 0.036 | -0.3880325 |
| 0.037 | -0.3288407 |
| 0.038 | -0.2754948 |
| 0.039 | -0.2276909 |
| 0.040 | -0.1851484 |
| 0.041 | -0.1476075 |
| 0.042 | -0.1148271 |
| 0.043 | -0.0865831 |
| 0.044 | -0.0626670 |
| 0.045 | -0.0428841 |
| 0.046 | -0.0270529 |
| 0.047 | -0.0150032 |
| 0.048 | -0.0065760 |
| 0.049 | -0.0016217 |
| 0.050 | 0.0000000 |
| 0.051 | -0.0015790 |
| 0.052 | -0.0062343 |
| 0.053 | -0.0138487 |
| 0.054 | -0.0243117 |
| 0.055 | -0.0375186 |
| 0.056 | -0.0533705 |
| 0.057 | -0.0717739 |
| 0.058 | -0.0926400 |
| 0.059 | -0.1158845 |
| 0.060 | -0.1414275 |
| 0.061 | -0.1691931 |
| 0.062 | -0.1991090 |
| 0.063 | -0.2311062 |
| 0.064 | -0.2651194 |
| 0.065 | -0.3010859 |
| 0.066 | -0.3389461 |
| 0.067 | -0.3786431 |
| 0.068 | -0.4201224 |
| 0.069 | -0.4633320 |
| 0.070 | -0.5082221 |
| 0.071 | -0.5547450 |
| 0.072 | -0.6028551 |
| 0.073 | -0.6525085 |
| 0.074 | -0.7036633 |
| 0.075 | -0.7562791 |
| 0.076 | -0.8103173 |
| 0.077 | -0.8657407 |
| 0.078 | -0.9225134 |
| 0.079 | -0.9806012 |
| 0.080 | -1.0399710 |
| 0.081 | -1.1005908 |
| 0.082 | -1.1624301 |
| 0.083 | -1.2254592 |
| 0.084 | -1.2896497 |
| 0.085 | -1.3549740 |
| 0.086 | -1.4214057 |
| 0.087 | -1.4889191 |
| 0.088 | -1.5574895 |
| 0.089 | -1.6270931 |
| 0.090 | -1.6977067 |
| 0.091 | -1.7693080 |
| 0.092 | -1.8418754 |
| 0.093 | -1.9153881 |
| 0.094 | -1.9898258 |
| 0.095 | -2.0651689 |
| 0.096 | -2.1413985 |
| 0.097 | -2.2184962 |
| 0.098 | -2.2964442 |
| 0.099 | -2.3752252 |
| 0.100 | -2.4548226 |
所以從列表數據結合圖形, 可以找到信賴區間的下限在 0.022~0.023 之間, 上限在 0.093~0.094 之間。